
5년간 쓴 아이패드가 깨져서 유리조각을 흘리고 다니길래, 새로운 아이패드를 구매했다.
아직 필름이 도착을 안해서 애플펜슬 펜촉을 기본으로 사용하니.. 미끌미끌 필기가 힘드러요
각설하고, 오늘도 진도 팍팍 나가신 교수님을 위해 복습 스따또
System Architectural Styles
시스템 아키텍처 스타일은 소프트웨어 아키텍처가 실제로 어떻게 구현되고 배치되는지에 따라 여러 유형으로 나뉜다.
Centralized Architecture(중앙 집중식 아키텍처)
중앙 집중식 아키텍처는 클라이언트-서버 아키텍처 모델이 대표적이다.
서버는 특별한 서비스를 구현하는 프로세스고, 클라이언트는 서버에 서비스를 요청하는 프로세스다.
클라이언트가 요청을 전송한 후에, 서버에서 응답을 받을 때까지 기다림이 발생한다. (blocking mode)

$t_1$은 클라이언트가 서버에 요청을 보내는 시간, $t_2$는 서버가 서비스를 제공하는 시간, $t_3$는 서버가 클라이언트에 응답을 전송하는 시간이다. 여기서 $t_2$의 시간을 최대한 줄이는 것이 소프트웨어 최적화라고 한다.
클라이언트와 서버 간의 통신은 다음과 같은 방식으로 구현될 수 있다.
- 비연결성 프로토콜(e.g. UDP): 기본 네트워크를 신뢰할 수 있을 때 사용하는 네트워크다. 효율적인 통신을 제공하지만, 전송 중에 발생하는 오류에 대응하기 쉽지 않다. 특정 작업이 여러 번 반복되도 문제가 발생하지 않는 경우, 멱등성이 있다고 하는데, 비연결성 프로토콜에서는 멱등성이 중요하다.
- 신뢰할 수 있는 연결 지향 프로토콜(e.g. TCP): 성능이 UDP에 비해 상대적으로 낮지만, 신뢰할 수 없는 광역 시스템(WAN)에서 안전하게 데이터를 전송할 수 있다.
클라이언트-서버 아키텍처는 물리적 계층에 따라 이중 계층과 삼중 계층 아키텍처로 나눌 수 있다.
- (물리적인) Two-tiered Architecture: 클라이언트 머신과 서버 머신이라는 두 가지 종류의 머신만 존재한다.
(a) UI를 클라이언트와 서버가 나눠가지는 것이다. 이 방식에서 클라이언트는 단순히 서버로부터 명령을 받고 화면에 출력하는 역할만을 하는데, 이를 dumb terminal이라고 한다. dumb terminal은 자체적인 처리 능력이 거의 없으며, 모든 연산을 서버가 수행하고, 터미널은 입력과 출력만을 담당한다.
(b) 애플리케이션을 GUI가 있는 프론트앤드와 나머지 애플리케이션 부분으로 나눈다. 프론트앤드는 나머지 애플리케이션과 애플리케이션 전용 프로토콜을 통해 통신해야한다. (e.g. ssh)
(c) 애플리케이션의 일부를 프론트앤드로 옮긴 방식이다. 클라이언트가 양식을 완전히 작성한 후에만 해당 양식이 처리된다.
(d) 애플리케이션의 대부분이 클라이언트 머신에서 실행되지만, 데이터베이스 항목에 대한 작업은 서버에서 처리된다. 주로 공장이나 회사에서 사용되는 방식이다.
(e) 클라이언트의 로컬 디스크에 데이터의 일부가 저장되는 방식이다. 자주 사용되는 데이터나 캐시 데이터 등을 로컬에 저장하여, 서버에 대한 요청을 줄이고 클라이언트 측의 성능을 향상시킨다.
(a)~ (c)를 Thin clients라고 부르며, (d)~(e)를 Fat clients라고 부르는데, Fat clients는 데이터베이스 빼고 클라이언트가 설계가 가능하기 때문에 개발・관리가 편하다.
- (물리적인) Three-tiered Architecture: 이 아키텍처에서는 서버가 때때로 클라이언트 역할을 할 수도 있다.
삼중 계층 아키텍처에서는 프로세싱 레벨의 일부를 구성하는 프로그램들은 별도의 서버에 위치해 있다. 이 구조는 기능을 계층화하여 각 계층이 독립적으로 동작하도록 설계된 것이다. 다수의 웹사이트를 조직할 때 사용하는 것이 이 아키텍처인데, 웹 서버가 사이트에 대한 입구 역할을 하며, 사용자의 요청을 받아 애플리케이션 서버로 전달한다. 여기 애플리케이션 서버에서 실제 처리가 진행되며, 애플리케이션 서버는 처리 과정에서 데이터베이스 서버와 통신한다. (애플리케이션 서버가 클라이언트이자 서버 역할)
아무래도 계층이 하나 더 존재하고, 데이터베이스 서버에서는 I/O가 관여하기 때문에 요청을 기다리는 UI 클라이언트의 대기 시간은 더 길어지게 된다.
이러한 다중 계층 아키텍처를 조직하는 방식은 다음과 같다.
- Vertical distribution(수직 분산): 분산 애플리케이션을 여러 논리적 계층으로 나누고, 각 계층의 컴포넌트들을 서로 다른 기계에서 실행한다.
- Horizontal distribution(수평 분산): 클라이언트 또는 서버를 물리적으로 분할하여, 논리적으로 동일한 역할을 수행하는 여러 부분으로 나눈다. 각 부분은 전체 데이터 세트의 일부를 처리하며, 이를 통해 작업 부하를 분산시켜 로드 밸런싱을 수행한다.
Decentralized Architecture(분산 아키텍처)
분산 아키텍처의 모델로는 Peer-to-peer Architecture가 있다.
이 아키텍처에서 모든 프로세스는 대등하고 대칭적이다. 즉, 시스템 내의 모든 프로세스가 동일한 역할을 수행할 수 있다.
각 프로세스는 동시에에 클라이언트이자 서버로 동작할 수 있다.
이러한 대등한 프로세스들은 오버레이 네트워크에서 조직된다. 각 노드는 네트워크의 다른 노드와 직접적으로 통신할 수 없더라도, 사용 가능한 경로를 통해 메시지를 전달한다.
- Structrued P2P: 의미없는 인덱스(semanitc-free index)를 사용한다. 각 데이터 항목은 고유한 키와 연결되며, 이 키는 인덱스로 사용된다. 해시함수(데이터를 입력받아 고유한 키 값을 출력하는 함수)를 사용하여 키를 생성하며, P2P 시스템은 (키, 값) 쌍을 저장해야한다. 이 키를 사용하여 연결된 데이터를 찾거나 저장할 수 있다. 노드들의 위치가 규칙에 의해 정의되어 있으며, 고정되어 있는 것이다. 제품들이 거의 고정되어 있는 스마트 시티는 Structured P2P를 사용한다.
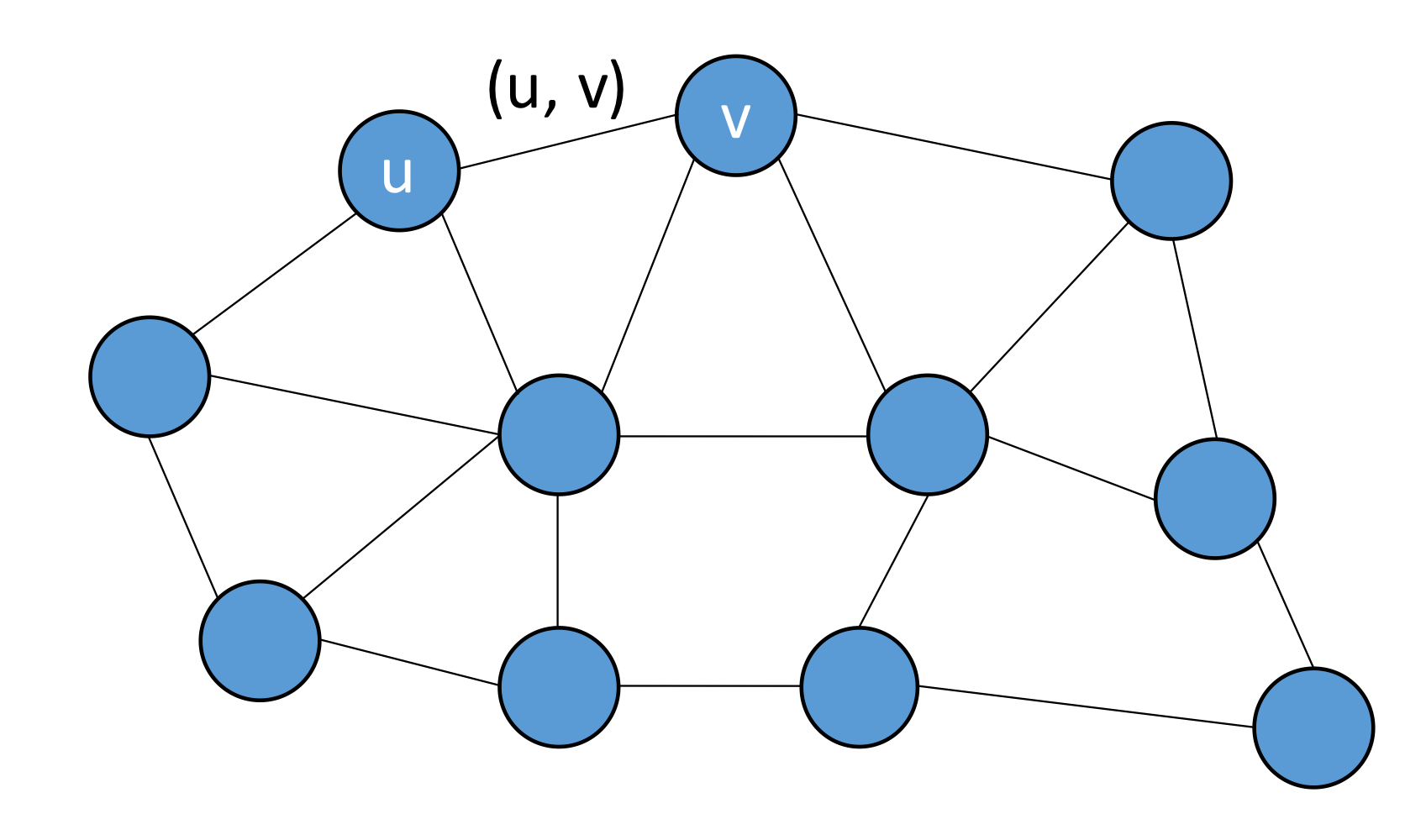
- Unstructured P2P: 각 노드는 임의의 이웃 목록(ad-hoc list of neighbors)을 가진다. 노드들이 특정 규칙 없이 임의로 다른 노드들과 연결되는 것이며, 결과적으로 생성된 오버레이 네트워크는 랜덤 그래프가 된다. 노드 u,v를 연결하는 엣지 (u,v)는 확률 P[(u, v)]로만 존재하는데, 이는 두 노드 간의 연결이 항상 존재하는 것이 아니라 일정한 확률에 의해 결정된다는 것이다.
노드들이 랜덤으로 연결되어 있는 비구조화 P2P에서는 데이터를 검색할 방법을 필요하다.
데이터를 검색하는 방법에는 Flooding과 Random walk이 있다.
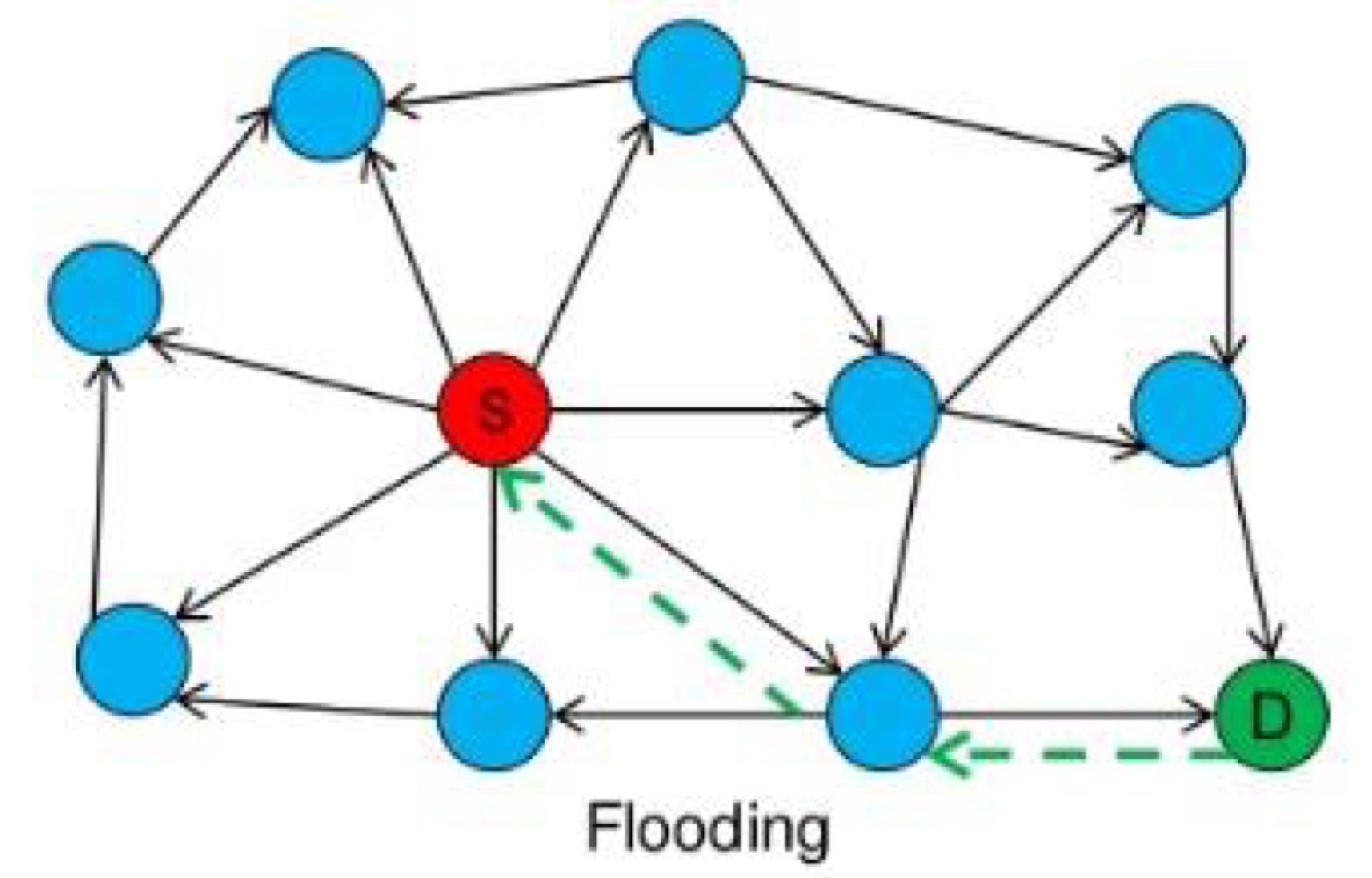
Flooding은 요청을 발생시킨 노드 u가 데이터 d에 대한 요청을 모든 이웃 노드에게 전달하는 방법이다. 요청을 받은 이웃 노드(v)가 데이터 d가 없다면 요청을 전송한 이웃 노드를 뺀 다른 이웃 노드들에게 다시 요청을 전달한다(재귀적). 요청을 한번 받았던 노드는, 해당 요청을 무시한다. 데이터 d는 가장 먼저 요청을 보낸 노드에 대해 응답을 전송하는데, 이것이 제일 짧은 경로이기 때문이다.
Flooding에는 Time-To-Live(TTL)이라는 규칙이 있는데, 요청이 최대 몇 번의 홉(hops)을 거쳐 전달될지 미리 정해놓는 것이다. 각 홉을 거칠 때마다 TTL 값이 감소하며, 0이 되면 요청이 더 이상 전달되지 않는다. 이 규칙으로 인해 요청이 무한으로 전파되는 것을 막을 수 있다.
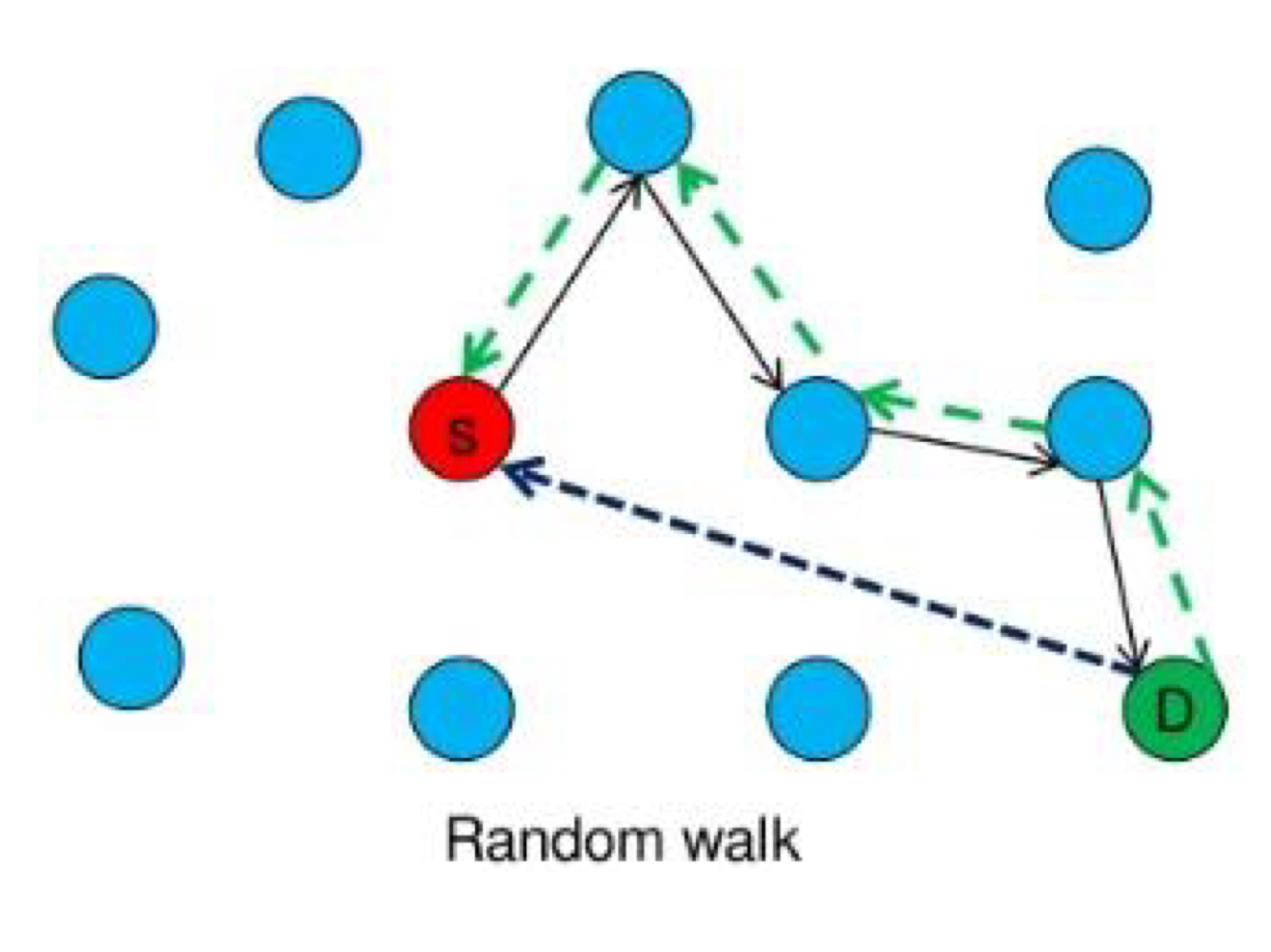
Random walk는 요청을 발생시킨 노드u가 데이터 d에 대한 요청을 임의의 이웃노드 v에 전달하는 방법이다. 이웃노드 v가 데이터 d를 가지고 있지 않다면, 다시 임의의 이웃노드에 전송한다. 이 과정은 데이터 d를 가진 노드가 발견될 때까지 계속된다. 쉽게 말하자면 랜덤으로 요청을 전송하다보면 언젠가 데이터 d에 도착하겠지~ 라는 방법이다.
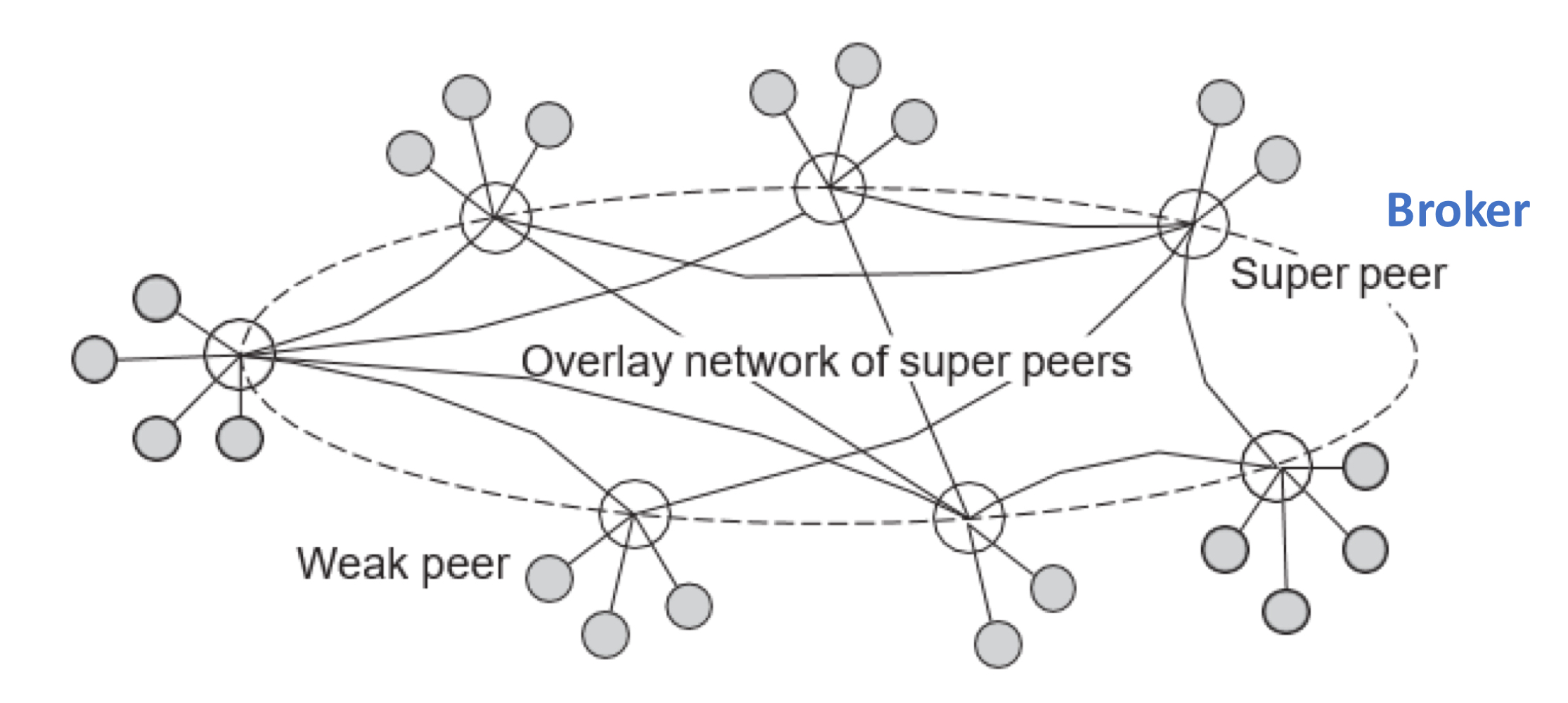
모든 노드들이 대등하고 대칭적인 P2P에서, 대칭성을 깨는 것이 합리적일 때가 존재한다.
비구조화된 P2P 네트워크에서 데이터를 검색할 때, 특정 노드를 인덱스 서버로 설정하여 검색 성능을 향상시킬 수 있다. 인덱스 서버에는 데이터의 위치에 대한 정보가 저장되어 검색 요청에 대한 응답을 빠르게 전송시켜줄 수 있다.
데이터가 어디에 저장할지를 결정하는 작업은 브로커(특정 역할을 부여받은 노드)를 통해 효율적으로 진행된다. 브로커는 네트워크 내에서 데이터의 최적 위치를 결정하고 저장한다.
이러한 특정 역할을 부여받은 노드를 Super-peer 라고 한다.
Hybrid Architecture
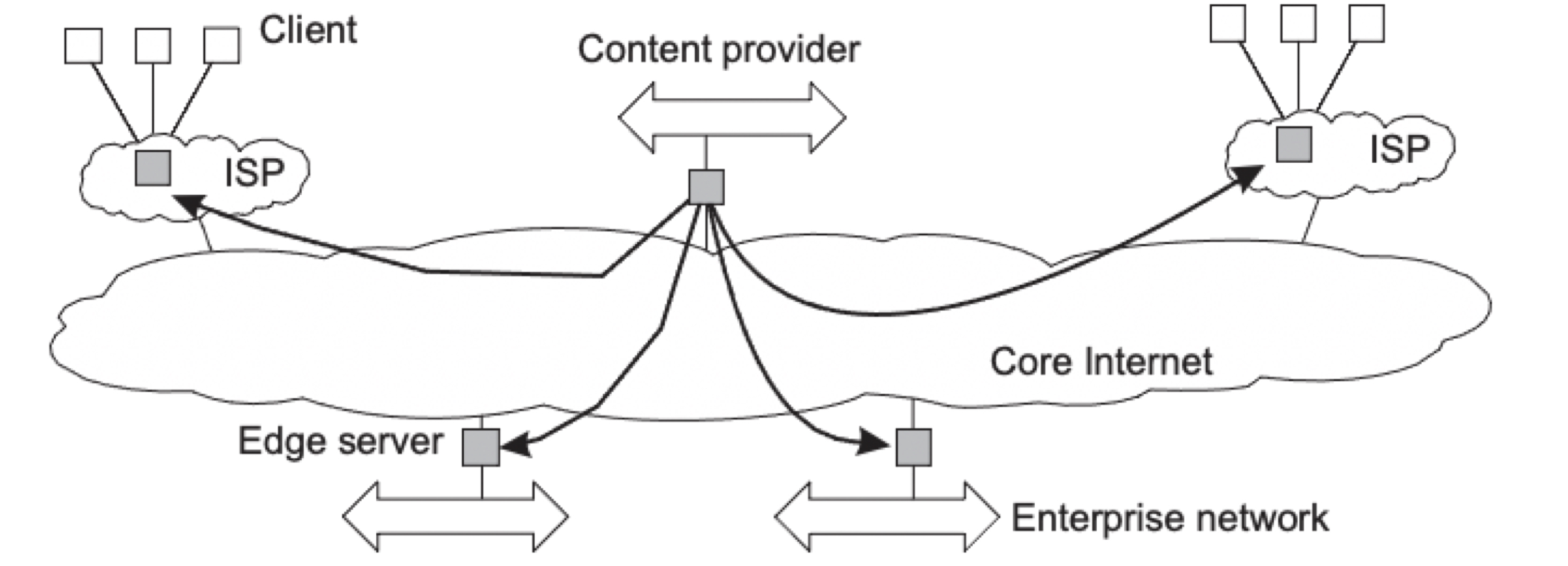
클라이언트-서버 아키텍처와 분산 아키텍처가 합쳐진 아키텍처다.
Edge-server system을 사용하는데, 서버들이 네트워크의 엣지 즉, 사용자와 가까운 곳에 배치되는 것이다. 이러한 서버는 주로 콘텐츠를 제공하는 역할을 한다. 서버가 사용자와 가까운 위치에 있기 때문에 데이터 전송 속도와 효율을 최적화 시킬 수 있다.
** 대학교 수업을 듣고 이해한 부분을 최대한 풀어서 작성한 글입니다.
틀린 정보가 존재할 수 있으며, 언제나 피드백은 환영입니다. **
'DKU > 분산처리' 카테고리의 다른 글
| Distributed System 7 (2) | 2024.09.30 |
|---|---|
| Distributed System 6 (0) | 2024.09.30 |
| Distributed System 4 (1) | 2024.09.20 |
| Distributed System 3 (5) | 2024.09.18 |
| Distributed Systems 2 (2) | 2024.09.09 |