
Coordination
중앙화된 시스템에서 '시간'은 모호하지 않다.
프로세스 A가 시간을 요청한 후에 프로세스 B가 시간을 요청하면, 당연히 프로세스의 A의 시간이 과거일 것이다.
하지만 분산 시스템에서의 '시간'은 어떨까?
분산 시스템에서의 '시간'은 많은 애플리케이션에 사용된다. 데이터 일관성 유지나, 이벤트 간의 인과관계 파악, 보안 같은 곳에 쓰인다.
문제는 각 시스템이 '자신만의 시계'를 가지고 있으며, 글로벌 시계가 존재하지 않는다는 것이다. 또한 자신만의 시계인 로컬 시계는 동기화되지 않을 수 있다.
글로벌한 상태를 유지하기 위해서는 이벤트가 발생한 순서를 알아야한다.
이는 물리적 시간과 논리적 시간으로 나누어서 볼 수 있다.
Physical Clocks
순서대로 줄 세우는 게 아닌 정확한 시간을 따르는 것이다.
Universal Coordinated Time(UTC)를 따르는 것인데, UTC는 세슘-133 원자의 1초당 진동횟수를 기준으로 설정되어 있다. 이는 매우 정확한 시간을 나타낸다.
물리적 시간을 사용할 때 신경써야 하는 것이 있는데, 시계의 동기화이다.
시계 동기화에서는 주로 두 가지 방법이 쓰인다.
- Precision(정밀성): 두 장치에 있는 시계 간의 오차를 특정 범위 내로 유지하는 것을 목표로 한다. 이는 내부 동기화가 목표인 것으로, 여러 장치 간의 시계가 일관된 상태를 유지하도록 한다.
- Accuracy(정확성): 시계가 특정 값 X에 정확히 맞추어져 있는 것을 목표로 한다. 이는 외부 동기화가 목표인 것으로, 모든 시계가 특정 참조 시간과 정확히 일치하도록 한다.
Cristian's Algorithm
중앙 시간 서버(UTC)가 존재한다고 가정한다. 프로세스 P는 이 시간 서버와 통신하여 자신의 시계를 설정한다.
P는 시간 요청 메시지를 보내고, 서버는 t라는 시간값을 포함한 응답을 보낸다.
P는 서버로부터 응답하는데 도착하는 시간 $T_{trans}$를 더해 자신의 시계를 설정한다.

설명하자면,
서버가 응답을 전송하고 그 응답이 클라이언트에게 도착할 때까지의 시간이 존재하는데, 이를 보정하는 방법인 것이다.
보정이 없이 클라이언트가 응답을 받으면 그것은 과거의 시간이 되기 때문이다.
RTT(Round Trip Time, 왕복시간) = $T_1 - T_0$ 이고, 대충 반으로 자르면 서버에서 클라이언트로 전송되는 시간이겠거니 하고 더해준다.
문제는,
중앙 시간 서버에 의존하기 때문에 중앙 시간 서버가 고장이 나버리면 시간 동기화가 불가능해진다.
또한, 다소 추상적인 값이다. RTT가 요청과 응답 간에 균등하게 배분될 경우에는 동기화 오류가 없지만, 비대칭적으로 배분되면 동기화에 오류가 발생한다.
Berkeley Algorithm
시간 서버가 따로 존재하지 않고, 여러 머신들 중 하나를 기준으로 삼는다.
기준이 된 머신은 master로, 나머지는 slave로 작동한다.
마스터가 주기적으로 각 슬레이브의 시간을 수집하며, 마스터는 네트워크에 연결된 슬레이브들의 현재 시간을 주기적으로 확인한다.
그리고 나서 마스터가 각 슬레이브에 시간 조정 명령을 내린다. 그러면 슬레이브가 마스터에게 시간의 차이를 알려주며, 시간을 조정한다.
만약 마스터가 실패할 경우에는 새로운 마스터가 선출된다.
마스터가 실제 시간은 아니지만 같은 시간을 가지고 있고, 내부 시계가 동기화되어 있다.
Logical Clocks
Happened-before 관계: 사건 간의 순서 정의
일반적으로 중요한 것은, 모든 프로세스가 정확히 동일한 시간을 합의하는 것이 아니다. 사건이 발생하는 순서에 대해 합의하는 것이 중요하다. 순서의 개념이 중요한 것이다. 이를 Happend-Bofore 관계라고도 하며, Lamport에 의해 정의된 개념이다.
- 만약 a와 b가 같은 프로세스에서 발생한 두 이벤트일 때, a가 b보다 먼저 발생하면 a → b 이다. 같은 프로세스 내에서 발생한 이벤트 간에는 명확한 순서가 존재한다.
- 만약 a가 메시지의 전송이고, b가 메시지의 수신이라면, a → b 이다. 메시지를 보내는 이벤트는 메시지 수신 이벤트보다 항상 먼저 발생한다.
- 만약 a → b 이고, b → c 라면, a → c 이다.
- 만약 A 와 B의 순서가 정해지지 않았다면, 이 두 사건은 동시성 관계에 있는 것이다. (A || B)
다만, Happened-before 관계는 잠재적인 인과관계만을 나타낸다. A → B 라고 해도, 둘 사이에 실제로 인과관계가 있다고는 보장할 수 없다.
그렇다면 어떻게 시스템에서 모든 프로세스가 Happened-before 관계에 맞춰 일관된 관점을 유지할 수 있을까?
각 이벤트에 e에 타임스탬프 C(e)를 부여하며 관점을 유지한다.
- P1 - 만약 a와 b가 같은 프로세스에서 발생한 두 이벤트이며 a → b라면, C(a) < C(b)이다.
- P2 - 만약 a가 메시지 m의 전송이고, b가 메시지 수신이라면, 역시 C(a) < C(b) 이다.
전역 시계가 없는 상태에선 어떻게 각 이벤트에 타임스탬프를 부여할 수 있을까?
각 프로세스마다 일관된 논리적 시계를 유지하며 타임스탬프를 부여한다.
각 프로세스 $P_i$는 지역 카운터 $C_i$를 유지하며 카운터를 조정한다.
- $P_i$내에서 새로운 이벤트가 발생할 때마다 $C_i$는 1씩 증가한다.
- 프로세스 $P_i$가 메시지 m을 보낼 때마다, 해당 메시지는 타임스탬프 $ts(m) = C_{i}$를 받는다.
- 프로세스 $P_j$가 메시지 m을 수신할 때, $P_j$는 자신의 지역 카운터 $C_j$를 max{$C_j$, ts(m)}로 조정한다. 수신된 메시지의 타임스탬프가 현재 프로세스의 카운터보다 크다면, 카운터를 그 값으로 업데이트 하는 것이다. 그런 다음, 애플리케이션에 메시지를 전달하기 전에 1단계를 실행한다.
속성 P1은 1번에 의해 충족되고, 속성 P2는 2번과 3번에 의해 충족되지만, 여전히 두 이벤트는 동시에 발생할 수 있다.
여러 프로세스에서 동일한 시간에 이벤트가 발생할 수 있기 때문이다.
따라서 같은 타임스탬프를 가진 이벤트가 발생하면, 프로세스 ID를 기준으로 구분해야한다.
Total-ordered Multicast
복제된 데이터베이스에서의 동시 업데이트는 어디에서나 동일한 순서로 반영되어야 한다.
위 사진처럼, 1000달러가 들어있는 데이터베이스에 업데이트를 진행한다고 가정하자.
지리적인 위치 문제로, 왼쪽의 데이터베이스에는 100달러가 먼저 저축되고, 1%의 이자가 붙었다. 오른쪽의 데이터베이스에는 1%의 이자가 붙은 후에야 100달러가 저축되었다. 각각의 데이터 베이스는 1111달러와 1110달러로 다른 결과를 가지게된다.
이렇게 적절한 동기화가 없을 경우, 무슨 오퍼레이션을 먼저 하느냐에 따라 값이 바뀌는 경우가 있다.
타임스탬프가 부여된 메시지를 사용하여 각 프로세스에서 메시지의 순서를 일관되게 처리할 수 있는 방법이 있다.
프로세스 $P_i$는 타임스탬프가 부여된 메시지 $m_i$를 보내고, 그 메시지는 로컬 큐 $queue_i$에 저장하는 것이다.
프로세스 $P_j$로 들어오는 모든 메시지는 타임스탬프에 따라 로컬 큐 $queue_j$에 저장되고, 다른 프로세스에 해당 메시지가 수신되었음을 ack한다.
프로세스 $P_j$는 $m_i$가 $queue_j$의 맨 앞에 있을 때 메시지 $m_i$를 애플리케이션으로 전달한다.
이때 $queue_j$내에 있는 다른 모든 프로세스 $P_k$의 메시지 $m_k$는 $m_i$보다 큰 타임스탬프를 가져야한다.
이 방식에서는 통신이 신뢰할 수 있으며, FIFO 순서로 처리되는 것을 가정한다.
Vector Clocks
Lamport 시계는 논리적 시계로서 사건 간의 순서를 추적하지만, 실제 인과관계는 완벽하게 보장하지 못한다.
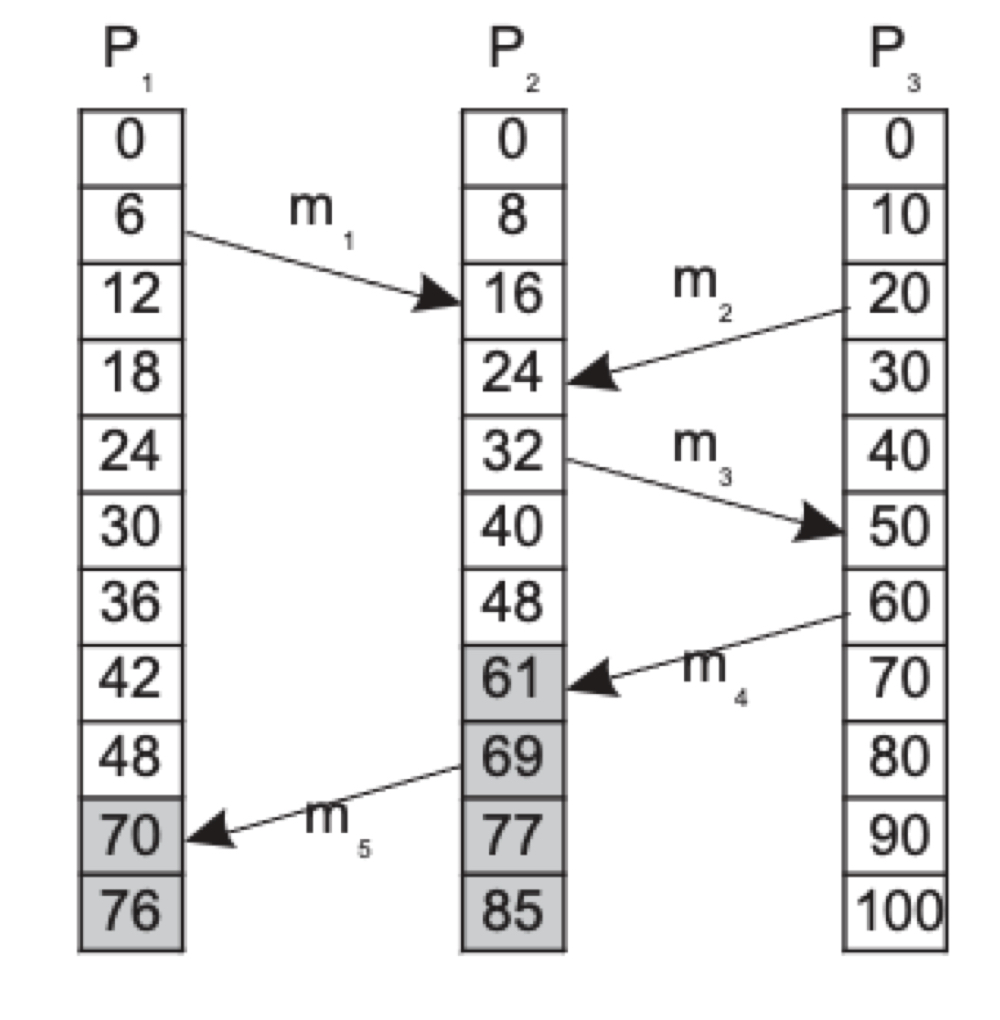
T = 16에 수신된 메시지 m1이 이벤트 a이고, T = 20에 전송한 m2가 이벤트 b라면, a가 인과적으로 b보다 먼저 발생했다는 결론을 내릴 수 없는 것이다.
벡터 시계를 사용하면, 각 프로세스 $P_i$는 벡터$VC_i$를 유지하게 된다.
$VC_i[i]$는 프로세스 $P_i$의 지역 논리적 시계를 나타내고, 만약 $VC_i[j] = k$라면, $P_i$는 $P_j$에서 k개의 이벤트가 발생했음을 알게된다.
이벤트를 실행하기 전에, 프로세스 $P_i$는 $VC_i[i]$의 값을 1 증가시킨다.
프로세스 $P_i$가 프로세스 $P_j$로 메시지 m을 보낼 때, 값을 1증가 시킨 후 메시지의 벡터 타임스탬프를 ts(m) = $VC_i$로 설정한다.
프로세스 $P_j$가 메시지 m을 수신하면, 각 k에 대해 $VC_j[k]$를 max{$VC_j[k]$, ts(m)[k]}로 설정 한 후 값을 1증가 시키고 메시지를 애플리케이션에 전달한다.
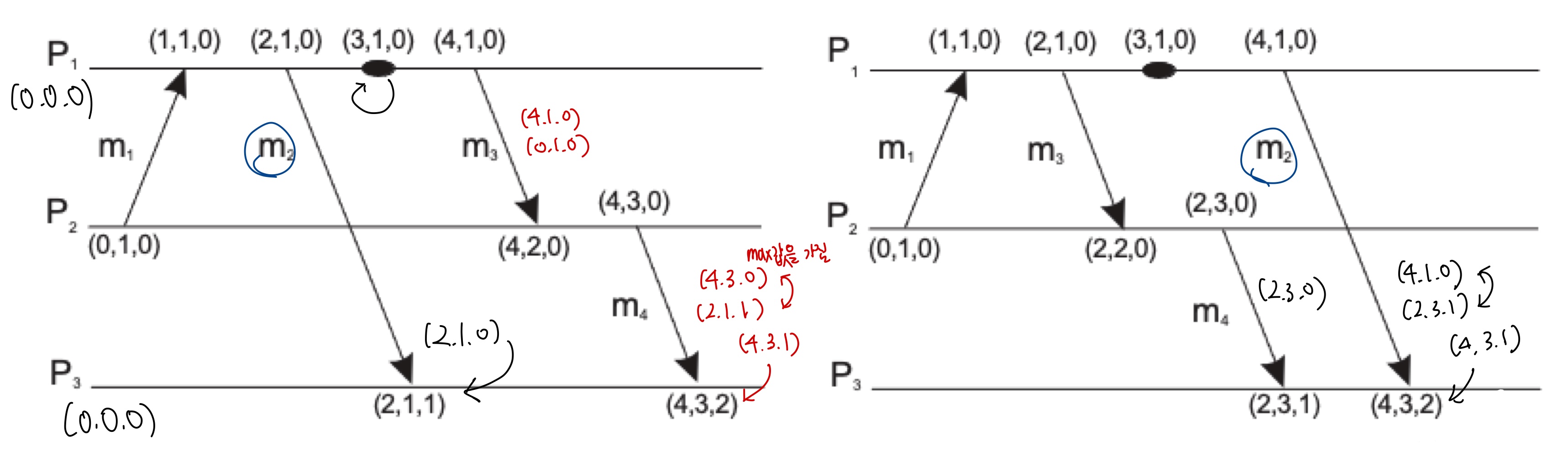
왼쪽 그림으로 설명하자면,
하나의 프로세스가 모든 프로세스의 각 지역 논리적 시계를 저장하고 있다는 것을 알 수 있다.
- P2에서 자신의 벡터 타임스탬프 값을 1 증가시키고 m1을 전송했다. (0, 1, 0)
- P1은 m1을 수신하고 자신의 벡터 타임스탬프 값을 1 증가시켰다. (1, 1, 0)
- P1은 자신의 벡터 타임스탬프 값을 1 증가시키고 m2를 전송했다. (2, 1, 0)
- P1은 자신의 벡터 타임스탬프 값을 1 증가시키고 이벤트를 발생시켰다. (3, 1, 0)
- P3는 m2를 수신하고 자신의 벡터 타임스탬프 값을 1 증가시켰다. (2, 1, 1)
- P1은 자신의 벡터 타임스탬프 값을 1 증가시키고 m3를 전송했다. (4, 1, 0)
- P2는 m3를 수신했다. (0, 1, 0)의 상태에서 (4, 1, 0)의 벡터 타임스탬프의 값을 받았으니 (4, 1, 0)이 되고, 메시지를 수신하고 자신의 벡터 타임스탬트 값을 증가시키니 (4, 2, 0)이 된다.
- P2는 자신의 벡터 타임스탬프 값을 1 증가시키고 m4를 전송했다. (4, 3, 0)
- P3는 m4를 수신했다. (2, 1, 1)의 상태에서 (4, 3, 0)의 백터 타임스탬프 값을 받았으니 (4, 3, 1)이 되고, 메시지를 수신하고 자신의 벡터 타임스탬프 값을 증가시키니 (4, 3, 2)가 된다.
벡터 VC(a)의 모든 요소가 VC(b)의 해당 요소보다 작거나 같다면, 이벤트 a는 이벤트 b보다 이전에 발생한 것으로 볼 수 있다.
벡터 VC(a)의 일부 요소는 VC(b)의 해당 요소보다 크지만, 다른 요소는 작을 경우, 동시적으로 발생한 사건으로 간주된다. 즉, a와 b에는 인과관계가 존재하지 않는다고 본다.
Causally-ordered Multicast: 인과적 순서 멀티캐스트
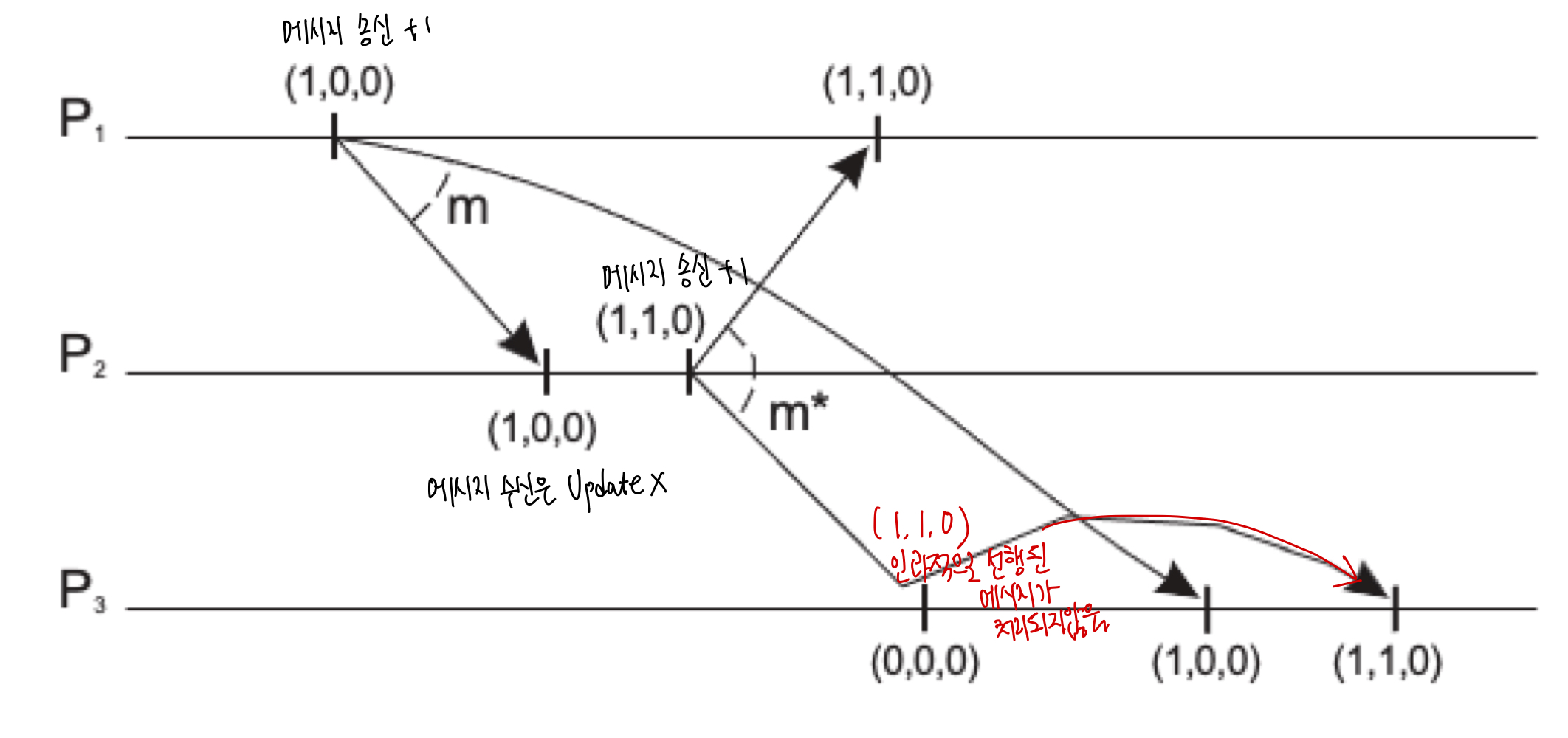
우리는 이제 인과적으로 선행된 메시지가 모두 처리된 이후에만 현재 메시지를 전달할 수 있음을 보장할 수 있게 되었다.
메시지를 보내는 프로세스는 백터 시계를 업데이트하고, 수신하는 프로세스는 수신된 메시지의 타임스탬프와 자신의 벡터 시계를 비교하여 인과적으로 선행된 모든 메시지가 처리된 후에만 해당 메시지를 애플리케이션에 전달한다.
여기가 분산처리 수업의 중간고사 범위이다.
양이 사악하고.. 방대하지만.. 그만큼 얻어가는게 많으므로 다음주까지 화이팅임미다
** 대학교 수업을 듣고 이해한 부분을 최대한 풀어서 작성한 글입니다.
틀린 정보가 존재할 수 있으며, 언제나 피드백은 환영입니다. **
'DKU > 분산처리' 카테고리의 다른 글
| Distributed System 12 (0) | 2024.11.05 |
|---|---|
| Distributed System 11 (0) | 2024.11.05 |
| Distributed System 9 (5) | 2024.10.14 |
| Distributed System 8 (7) | 2024.10.07 |
| Distributed System 7 (2) | 2024.09.30 |