
Replication: 복제
복제의 목적은 가용성(availability), 신뢰성(dependability), 또는 성능(performance)을 향상시키는 것이다.
이때 복제 가시성(replica visibility)에 대한 정보가 없어도 이러한 목적을 달성할 수 있어야한다.
분산 시스템인만큼, 시스템 내에서 상태의 복제를 숨겨서 사용자나 애플리케이션이 복제를 인식하지 못하도록 하는 복제 투명성(replication transparency)이 중요하다.
- 활성 복제(Active replication)는 여러 복제본이 동시에 활성 상태로 작동하여 요청을 처리한다.
- 기본/대기 복제(Primary/Stand-by replication)는 하나의 기본 복제본이 활성 상태로 작동하고, 대기 복제본은 기본 복제본이 장애가 발생한 경우에만 활성화된다.
분산 시스템에서는 데이터와 서버가 복제 대상이며, 복제본 간의 일관성 유지(consistent)가 가장 큰 문제이다.
Replicaiton System Model
일관성의 측면에서 복제 모델은 다음의 두 가지 극단적인 모델 사이에 위치할 수 있다.
- 완전 동기 모델(Totally synchronous model): 모든 복제본 간의 완벽한 동기화가 이루어지는 모델
- 비동기 모델(Asynchronous model): 복제본이 비동기적으로 업데이트되며, 일시적인 일관성 부족(temporal inconsistency)을 허용하는 모델
캐싱 또는 서버를 클라이언트 근처에 복제하여 지연을 줄임으로써 성능을 향상시키고, 프로세스 및 네트워크에 장애가 발생해도 서비스에 접근할 수 있도록 하여 가용성을 거의 100%에 가깝게 유지한다. 또한 장애가 발생해도 엄격하게 올바른 동작을 보장하여 결함을 허용한다.
Replication protocol model: 복제 프로토콜 모델
- 요청: 활성 복제와 수동 복제 방식에 따라 따라 요청을 처리한다.
- 서버 간 조정: 메시지 순서를 보장하는 방법으로 FIFO, 인과순서(causal), 전체순서(total)를 사용한다.
- 실행: 실제 연산을 수행하는 단계이다.
- 합의 조정: 데이터베이스에서는 일관성을 위해 합의가 필수적이다. 반면, 분산시스템에서는 순서 보장만으로 충분하다.
- 클라이언트 응답: 동기적 응답과 비동기적 응답 중 하나로 클라이언트에 응답한다.

Active replication(state machine approach): 활성 복제
활성 복제의 주요 특징은 다음과 같다.
- 결정적 실행(Deterministic execution): 모든 복제본은 동일한 클라이언트 요청의 순서를 받아 동일하게 처리한다.
- 요청은 Atomic totally ordered muticast를 통해 각 복제본에 전송된다.
- 요청 순서가 항상 동일하게 유지되기 때문에 복제본 간의 별도의 합의가 필요하지 않다.
Passive replication(primary-backup relicaiton): 수동 복제
수동 복제의 주요 특징은 다음과 같다.
- 비결정적 실행: 요청 처리 과정에서 모든 복제본이 동일한 상태에 있지 않을 수도 있다. 즉, 주 서버(primary)가 요청을 처리하고, 변경 사항이 백업 서버로 전파된다.
- 뷰 동기화: 뷰(view)란, 현재 활성 상태로 연결된 서버들의 목록을 의미한다.
- 처리된 요청을 백업 서버로 전송하기 때문에 서버 간의 조정이 필요하지 않다.
Semi-active repliacation
세미-활성 복제의 주요 특징은 다음과 같다.
- 비결정적 실행
- 요청은 atomic totally ordered multicast를 통해 모든 복제본에 전송된다.
- 뷰 동기화를 사용하여, 리더가 자신의 선택을 팔로워들에게 알린다. 이를 통해 리더의 결정이 전체 복제본에 반영된다.
Semi-passive replication
세미-수동 복제의 주요 특징은 다음과 같다.
- 뷰 동기화가 없는 수동 복제와 같다.
- 공격적인 타임아웃을 설정하여 프로세스의 충돌 가능성을 빠르게 탐지할 수 있다. 잘못된 실패 감지에 따른 비용이 크지 않기 때문에, 충돌이 의심되는 프로세스를 쉽게 탐지할 수 있다.
Consistency: 일관성
만약 분산시스템에서 오브젝트나 데이터가 공유된다면, 동시 접근을 관리하여 상태의 일관성을 보장할 필요가 있다.
동시 접근을 제어하기 위한 해결방안은 다음과 같다.
- 해결책1: 공유 객체 자체가 동시 호출을 처리할 수 있도록 만든다.
- 해결책2: 객체가 속해 있는 시스템이 동시 접근 관리의 책임을 진다.
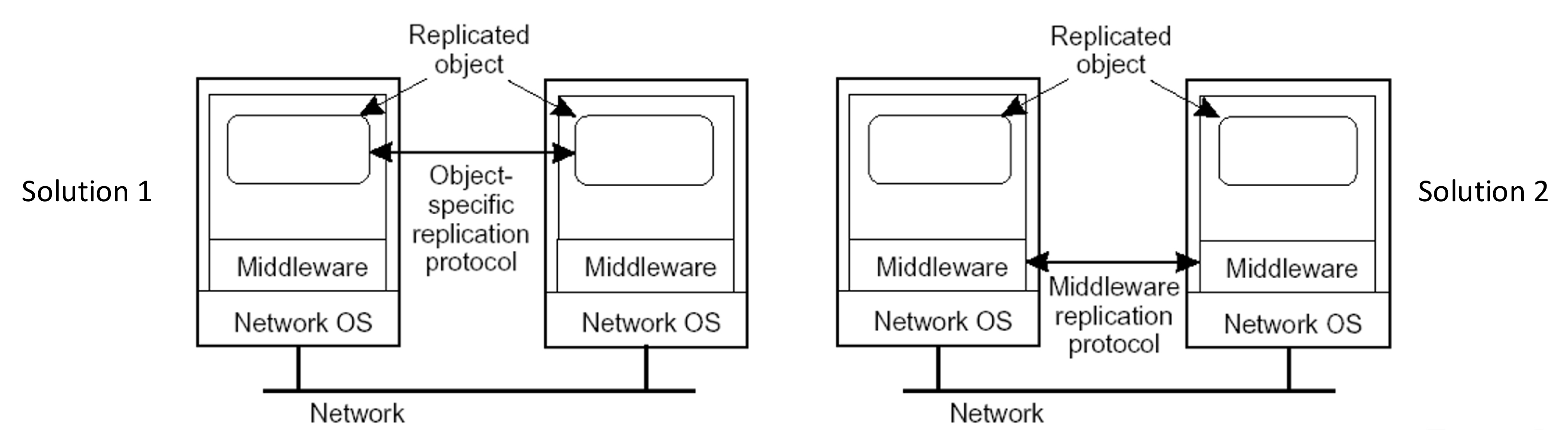
그렇다면 복제 데이터 객체는 어떻게 관리해야할까?
- 해결책1: 객체가 복제를 인식하도록 설계하거나, 객체에 특화된 복제 프로토콜을 사용하여 복제본을 관리한다.
- 해결책2: 분산 시스템 자체가 복제본 관리의 책임을 가진다. 시스템이 모든 객체의 복제 일관성을 유지하도록 하여 중앙화된 방식으로 복제를 관리한다.
복제본의 일관성을 유지하기 위해서는 모든 충돌하는 연산이 동일한 순서로 실행되도록 보장해야 한다.
충돌하는 연산의 종류로는, 읽기-쓰기 충돌과 쓰기-쓰기 충돌이 있다.
충돌하는 연산에 대해 글로벌 순서를 보장하는 것은 비용이 많이 들며, 이는 시스템의 확장성을 저하시킬 수 있다.
이러한 문제를 완화하기 위해, 일관성 요구 사항을 완화하여 글로벌 동기화를 피하는 방법도 고려할 수 있다.
일관성 요구 사항을 완화한다는 것은 뭘까?
일단 업데이트가 원자적 연산으로 실행될 필요성을 완화시킨다. 또한 글로벌 동기화를 요구하지 않고, 각 제본이 항상 동일하지 않을 수 있는 것을 허용한다.
그렇다면 일관성을 어느 정도까지 완화시킬 수 있을까?
이는 복제된 데이터의 접근 및 업데이트 패턴에 따라 달라지며, 복제된 데이터의 사용 목적에 따라서 달라질 수도 있다.
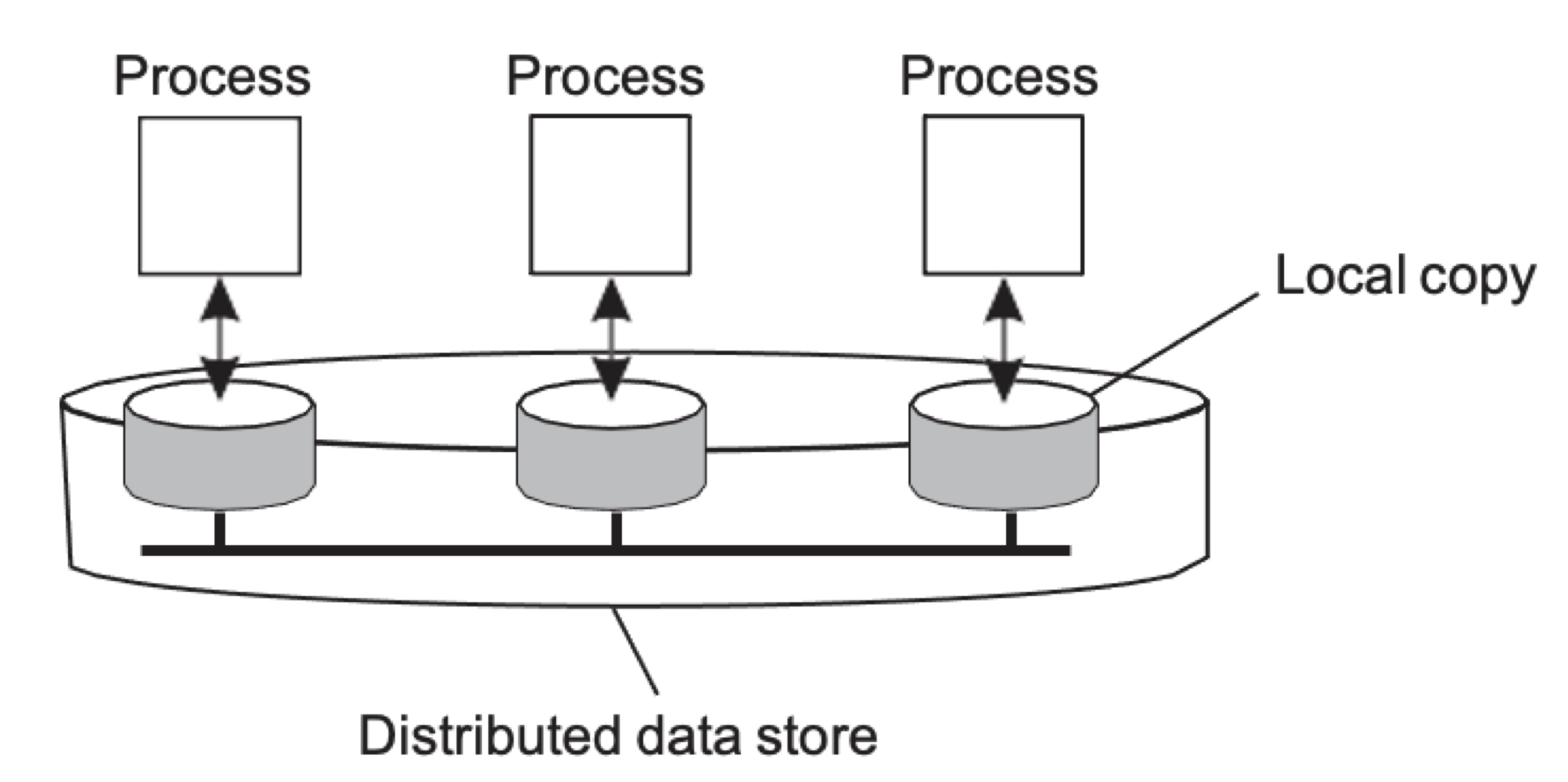
Data-centric Consistency Model: 데이터 중심 일관성 모델
일관성 모델이란 프로세스와 분산된 데이터 저장소 간의 계약이라고 볼 수 있다. 이 계약에서는 동시성이 있는 상황에서 읽기 및 쓰기 연산의 결과가 어떻게 되는지를 데이터 저장소가 명확히 규정한다. 여기서 데이터 저장소란, 분산된 저장소의 집합으로 구성된다.
일관성 모델은 강한 일관성 모델과 약한 일관성 모델로 나뉜다.
강한 일관성 모델은 공유 데이터에 대한 연산이 동기화된다.
- 절대적 글로벌 시간을 기준으로 한 엄격한 일관성(strict consistency) 모델
- 직렬화(serializability) 사용, 순차적인 일관성(sequential consistency) 모델
- 인과 관계가 있는 연산만을 유지하는 인과적 일관성(causal consistency) 모델
- 각 프로세스의 개별 연산 순서만을 유지하는 FIFO 일관성 모델
약한 일관성 모델은 공유 데이터가 잠기고 잠금 해제될 때만 연산이 동기화된다.
- 동기화가 느슨하게 유지되는 일반적인 약한 일관성(general weak consistency) 모델
- 공유 데이터에 접근하기 전에 락을 해제하는 Release 일관성 모델
- 특정 엔트리에 접근할 때만 동기화를 유지하는 Entry 일관성 모델
일관성 모델이 약해질수록, 확장 가능한 해결책을 세우기 쉬워진다.
Strict Consistency Model: 엄격한 일관성 모델
엄격한 일관성 모델에서는 읽기 연산이 항상 가장 최근의 쓰기 연산 결과를 반환한다는 가정을 한다.
또한 절대적 글로벌 시간이 존재하고, 데이터 저장소가 엄격한 일관성을 유지한다고 가정한다.
하지만 절대적 글로벌 시간을 구현하는 것은 불가능하며, 특정 시간 간격 동안 단일 연산만 수행된다는 보장이 없다. 동일한 시간 간격 동안 여러 연산이 동시에 수행될 수도 있기 때문이다.
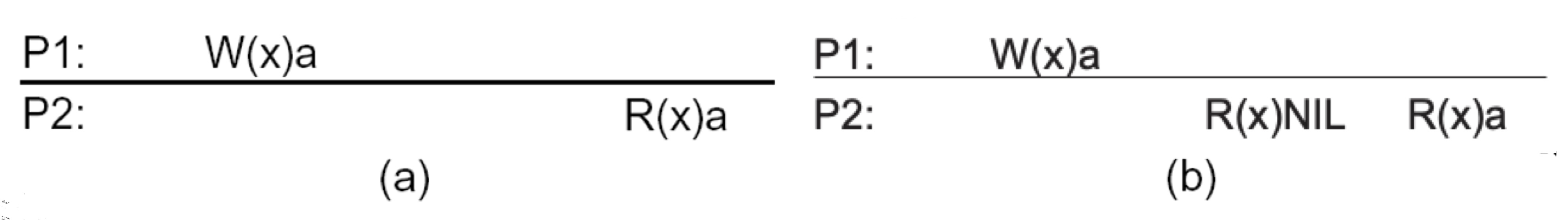
그림 (a)는 x에 a를 쓰는 연산이 수행된 후, x를 읽고 a를 반환하는 연산이 수행되어 엄격한 일관성이 유지되는 그림이다.
하지만 그림(b)는 쓰기 연산을 수행하고, 아무것도 없는 x를 읽은 후에 a를 읽었다. 이는 엄격한 일관성이 깨진 것이다.
일반적인 순차 실행 환경에서는 다른 프로그램이 간섭하지 않을 때의 일관성과 동일한 일관성을 갖는다.
엄격한 일관성을 가진 데이터 저장소에서는 모든 쓰기 연산이 즉시(instatnaneously) 모든 프로세스에 반영되며, 절대적 글로벌 시간이 유지된다.
데이터 항목이 변경되면, 그 이후의 모든 읽기 연산은 변경된 값을 반환한다. 이때 변경 직후이거나, 읽기를 수행하는 프로세스의 위치와 관계없이 최신 값이 반환된다.
읽기 연산 이후에 쓰기 연산이 아무리 빨리 수행되더라도, 읽기 연산은 언제나 현재 값을 반환한다.
하지만, 분산 시스템에서는 절대적 시간 개념을 유지할 수 없기 때문에 엄격한 일관성 모델을 구현하는 것은 사실상 불가능하다.
Sequential Consistency Model: 순차적인 일관성 모델
순차적인 일관성 모델은 엄격한 일관성 모델보다는 살짝 약한 모델이다.
데이터 저장소가 순차적 일관성을 가지려면 다음 두 가지 조건을 만족해야 한다.
- 모든 프로세스의 읽기 및 쓰기 연산 결과가 마치 하나의 순차적 순서로 실행된 것과 동일해야 한다.
- 각 프로세스의 연산은 그 프로세스가 정의한 프로그램 순서대로 나타나야 한다.

왼쪽 그림은 P1이 변수 x에 값 a를 쓰는 연산을 했고, 이후 P2가 변수 x에 값 b를 쓰는 연산을 수행했다. P3와 P4는 b를 먼저 읽고난 후에 a를 읽는 연산을 수행한다. 이는 b의 쓰기 연산이 먼저 수행된 것처럼 보이며, 하나의 순차적 순서로 실행된 것처럼 보인다.
하지만 오른쪽 그림의 P3는 b를 먼저 읽었지만, P4는 a를 먼저 읽었다. 순차적 순서가 존재 하지 않으며, 이는 일관성 모델에 해당하지 않는다.
Linearizability Model: 선형화 가능성 모델
엄격한 일관성 모델보다는 약하지만 순차적 일관성 모델보다는 강한 모델이다.
글로벌 시계를 사용하여 각 연산에 타임스탬프를 부여하지만, 이 시계는 유한한 정밀도를 가진다.
선형화 가능 데이터 저장소의 조건은 다음과 같다.
- 모든 읽기 및 쓰기 연산 결과가 마치 하나의 순차적 순서로 실행된 것과 동일해야 한다.
- 각 프로세스의 연산은 그 프로세스가 정의한 프로그램 순서대로 나타나야한다.
- 추가조건: 만약 연산 OP1(x)의 타임스탬프가 OP2(y)보다 작다면, 이 순서에서도 OP1(x)가 OP(y)보다 먼저 발생해야 한다.
조건을 보면 알겠지만, 선형화 가능한 데이터 저장소는 순차적 일관성도 충족한다.
또한 동기화된 시계를 사용하여 각 연산의 순서를 정렬하고 이를 기준으로 일관성을 유지한다.
Causal Consistency Model: 인과적 일관성 모델
순차적 일관성 모델보다는 약한 모델이다.
이 모델은 이벤트 간의 인과관계를 구분한다.
만약 이벤트 B가 이벤트 A에 의해 발생하거나 영향을 받았다면, 모든 프로세스는 먼저 A를 본 후에 B를 봐야한다.
인과적 일관성을 만족하는 데이터 저장소의 조건은 다음과 같다.
- 잠재적으로 인과 관계가 있는 쓰기 연산은 모든 프로세스에서 동일한 순서로 나타나야한다.
- 동시성을 가진 쓰기 연산은 서로 다른 시스템에서 다른 순서로 보일 수 있다.
일관성의 유지는 연산 간의 의존성(dependency)에 의해 이루어진다.

P1에서 a를 쓴 후에, P2에서 b를 썼는데, 그 사이에 a의 읽기 연산이 존재하기 때문에 P1의 a쓰기 연산과 P2의 b쓰기 연산은 서로 상관관계가 있다고 본다. a의 결과를 보고 b를 쓴 것이니까! 하지만 여기서 c의 쓰기 연산은 독립적인 연산으로 보고, 연산들의 중간에 껴도 신경을 쓰지 않는다.
이처럼 인과적 일관성 모델에서는 동시 쓰기 연산이 다른 순서로 보일 수 있기 때문에, 순차적 일관성이나 엄격한 일관성에서는 허용되지 않는 시퀀스도 허용된다.
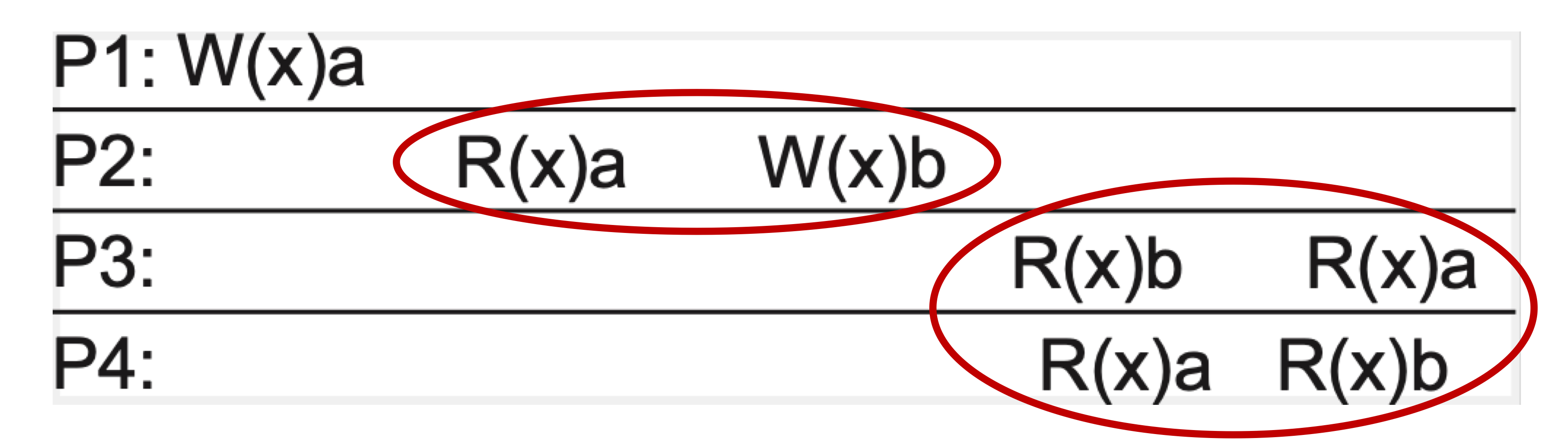
위 그림은 P2에서 a의 읽기가 이루어진 후에 b의 쓰기가 실행됐으므로, 서로 인과관계가 있다.
하지만 P3에서는 b의 읽기가 먼저 이루어지고, P4에서는 a의 읽기가 먼저 이루어지므로 인과적 일관성이 이루어지지 않고 있다.
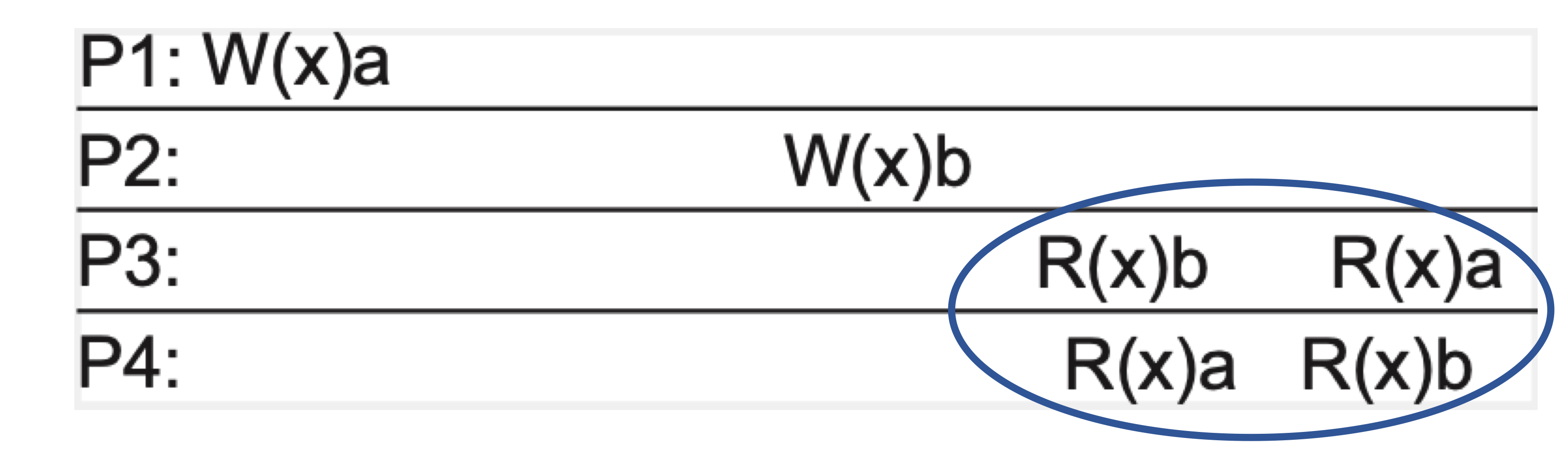
위 그림에서의 P1의 a쓰기 작업과 P2의 b쓰기 작업은 서로 독립적인 연산이다.
따라서 인과적 관계가 없으므로, 누가 먼저 읽히느냐에 대한 건 상관없다.
FIFO Consistency Model
인과적 일관성 모델보다 더 약한 모델이다.
이 모델은 인과관계가 있는 쓰기 연산의 순서를 모든 프로세스에서 동일하게 보장하는 요구 사항을 제거했다.
FIFO 일관성을 만족하는 데이터 저장소의 조건은 다음과 같다.
- 한 프로세스에서 수행된 쓰기 연산은 모든 다른 프로세스에서 발생한 순서대로 보인다.
- 다른 프로세스에서 수행된 쓰기 연산은 각 프로세스에서 다른 순서로 보일 수 있다.
쉽게 말하자면, FIFO 일관성은 프로세스 간의 관계를 무시하는 것이다.
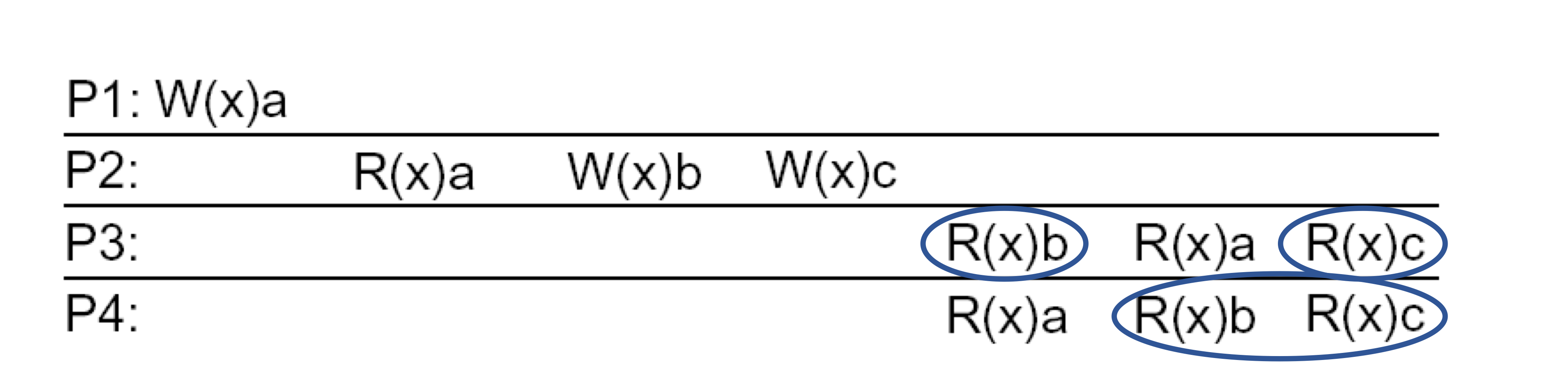
인과적 일관성 모델이였으면, P1의 a쓰기 연산과 P2의 b쓰기 연산은 인과관계가 있으므로, 순서가 유지되어야 한다.
하지만 FIFO 일관성 모델에서는 프로세스 간의 관계를 무시하고, 한 프로세스 내에서 발생한 쓰기 연산에 집중한다.
따라서 P2에서 수행된 b쓰기 작업과 c쓰기 작업이 일관성을 가져야하는 것이다.
독립적으로 수행된 a쓰기 작업은 일관성과 연관이 없다.
Weak Consistency Model: 약한 일관성 모델
이 모델은 임계 영역 내 데이터의 최종 결과만 모든 복제본에 반영되며, 중간 결과는 모든 복제본에 순서대로 전파될 필요가 없다.
동기화 변수, 즉 락(lock)이 사용된다.
다음은 약한 일관성 모델의 특징이다.
- 여기서 동기화 변수 접근은 순차적 일관성을 유지한다. 모든 프로세스는 동기화 변수에 대한 연산을 동일한 순서로 볼 수 있는 것이다.
- 이전에 수행된 모든 쓰기 연산이 전체 복제본에 반영되기 전까지는 동기화 변수에 대한 어떠한 연산도 실행될 수 없다. 즉, 동기화 변수에 접근하기 이전의 쓰기 연산이 완료되도록 보장한다.
- 로컬 복제본에서의 모든 쓰기 연산은 강제적으로 수행된다.
- 동기화 변수에 대한 모든 이전 연산이 완료될 때까지는 데이터 항목에 대한 읽기나 쓰기 연산을 수행할 수 없다.
- 이 모델에서는 프로세스가 동기화 변수를 통해 임계 영역에 진입할 때 가장 최신의 데이터 값을 보장받을 수 있다.
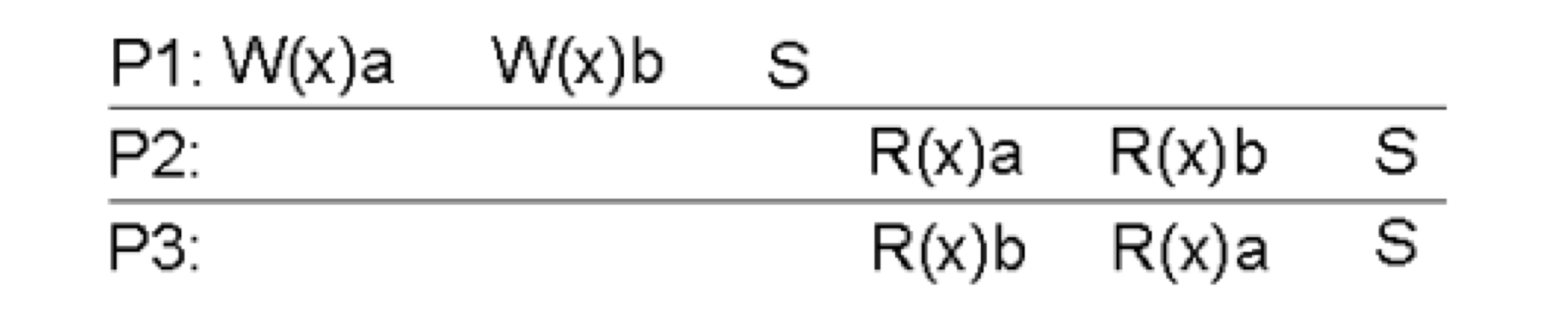
P1은 a쓰기 작업과 b쓰기 작업을 실행하고 S(synchronize)를 실행한다.
P2와 P3는 아직 동기화가 되지 않았으며, 동기화가 되기 전까지는 일관성이 보장되지 않는다.
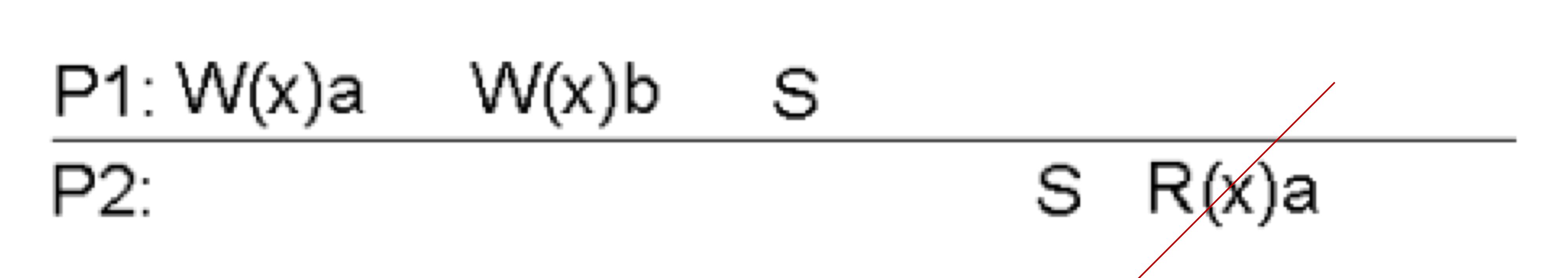
이제 P2가 동기화 지점을 지났다.
P1 에서 동기화 할 때, x의 가장 최근 값은 b가 되므로 동기화된 P2는 a를 읽을 수 없게 된다.
핵심 요점은, 개별 읽기와 쓰기가 아니라 연산 그룹 전체에 대해 일관성을 제공한다는 것이다. 이는 대부분의 접근이 군집 형태로 발생할 때 유용하다.
또한 일관성이 유지되는 시간만 제한하며, 일관성의 형태는 제한하지 않는다.
연산 그룹 간에 순차적 일관성을 보장하기 때문에, 오버헤드가 적게 발생한다.
Release Consistency Model
약한 일관성 모델에서는 임계영역에 진입하는 것과 나가는 것을 구분하기 어렵다는 문제가 있다.
이를 해결하기 위해 하나의 동기화 연산(S) 대신, acquire와 release 라는 두 가지 동기화 연산을 사용한다.
릴리스 일관성 모델에서는 Barrier라는 메커니즘이 사용된다.
이는 모든 프로세스가 특정 단계(n)을 마치기 전까지 다음 단계(n+1)를 진행하지 못하게 하는 동기화 메커니즘이다.
프로세스가 베리어에 도착하면 다른 모든 프로세스가 도착할 때까지 기다려야한다.
베리어에서 출발하는 것은 acquire와 관련이 있으며, 베리어에 도착하는 것은 release와 관련이 있다.

P1에서 락을 건 후에 a를 쓰고, b를 쓰고 락을 해제 했다.
따라서 락을 건 P2는 b만을 읽을 수 있으며, 따로 락을 걸지 않은 P3는 a를 읽을 수 있다.
릴리스 일관성을 만족하는 데이터 저장소의 조건은 다음과 같다.
- 공유 데이터에 대한 읽기 또는 쓰기 연산을 수행하기 전에, 해당 프로세스가 수행한 모든 이전 acquire연산이 성공적으로 완료되어야 한다.
- release 연산이 수행되기 전에 해당 프로세스의 모든 읽기와 쓰기 연산이 완료되어야 한다.
- 동기화 변수에 대한 접근은 FIFO 일관성을 유지하지만, 순차적 일관성은 요구되지 않는다.
지연 릴리스 일관성은 필요할 때까지 업데이트를 지연하여 성능을 향상시킨다.
Entry Consistency Model
이 모델에서 동기화 변수는 전체 공유 데이터가 아니라 개별 공유 데이터 항목과 연관된다.
엔트리 일관성을 만족하는 데이터 저장소의 조건은 다음과 같다.
- acquire 연산 시, 보호되는 데이터(guarded data)에 대한 모든 원격 변경 사항이 가시적이여야 한다.
- 업데이트를 수행하기 전, 프로세스는 임계 영역에 진입해야 한다.
- 비독점적(non-exclusive) 모드 접근의 경우, 프로세스는 동기화 소유자와 확인해야한다.

P1에서 x에 대한 락이 걸리고, a쓰기 연산을 수행한다음 y에 대한 락이 걸렸다. 이는 개별 공유 데이터 항목에 대한 동기화 변수를 사용한다는 것이다.
P2에서 x에 대한 락을 건 후에 a읽기 연산을 수행하고, y에 대한 읽기 연산을 수행했지만 y에 대해서 NIL값을 받았다. 이는 y에 대한 acquire 가 없기 때문이다. 때문에 y에 대해 락을 건 P3는 b라는 값을 반환받을 수 있었다.
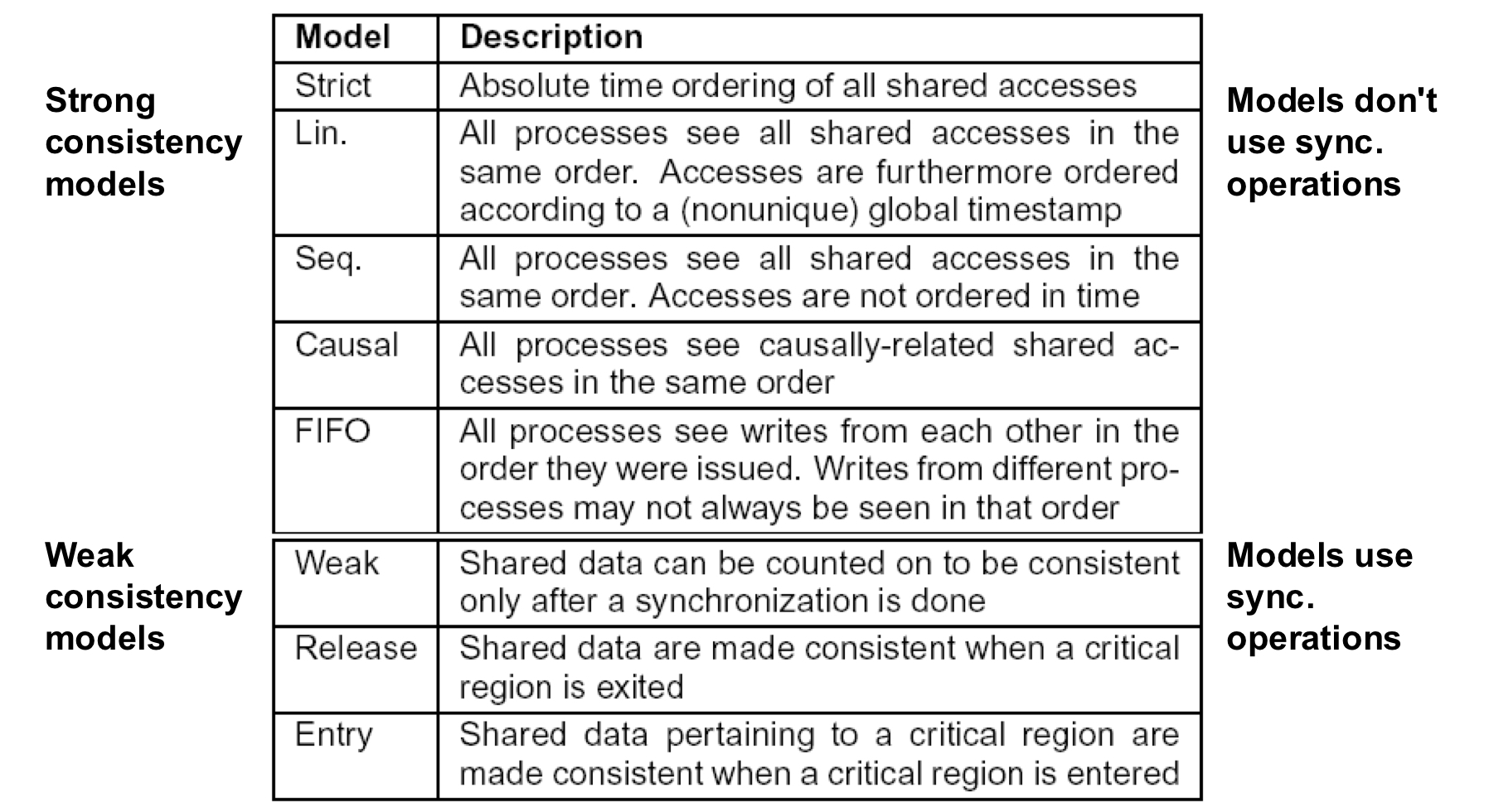
이제까지 배운 일관성 모델들을 정리해 놓은 것이다.
교수님께서 넌지시 시험에 나올 것이라는 힌트를 주었으니, 달달 외우도록 하자.
** 대학교 수업을 듣고 이해한 부분을 최대한 풀어서 작성한 글입니다.
틀린 정보가 존재할 수 있으며, 언제나 피드백은 환영입니다. **
'DKU > 분산처리' 카테고리의 다른 글
| Distributed System 14 (1) | 2024.11.18 |
|---|---|
| Distributed System 13 (2) | 2024.11.11 |
| Distributed System 11 (0) | 2024.11.05 |
| Distributed System 10 (1) | 2024.10.17 |
| Distributed System 9 (5) | 2024.10.14 |