
Fault Tolerance
Dependability: 신뢰성
컴포넌트는 클라이언트에게 서비스를 제공한다. 그리고 서비스를 제공하기 위해 그 컴포넌트는 다른 컴포넌트의 서비스를 필요로 할 수 있다. 즉, 컴포넌트는 다른 컴포넌트에 의존할 수 있다는 것이다.
다음은 신뢰성과 관련된 요구사항들이다.
- Availability(가용성): 사용 가능
- Reliability(신뢰성): 서비스의 연속적 제공
- Safety(안전성): 아주 낮은 재앙(catastrophes) 가능성
- Maintainability(유지보수성): 수리하기 용이
컴포넌트 C가 시간 T = 0에서 정상적으로 작동한 상태에서 [0, t) 동안 정상적으로 작동할 확률을 Reliability R(t) 라고한다.

- Mean Time To Failure, MTTF (평균 고장 시간): 컴포넌트가 고장날 때까지의 평균 시간
- Mean Time To Repair, MTTR (평균 수리 시간): 컴포넌트를 수리하는데 걸리는 평균 시간
- Mean Time Between Failures, MTBF (평균 고장 간격): MTTR와 MTTR의 합
컴포넌트 C가 [0, t)의 구간에서 가동 상태였던 평균 비율을 Availability A(t)라고 한다. 장기 가용성은 A(∞)라고 한다.
이때, A = MTTF/MTBF 로 구할 수 있다.
신뢰성과 가용성은 실패에 대한 명확한 정의가 있을 때만 의미를 가진다.
컴포넌트의 실패는 어떻게 발생하는 것일까?
Fault가 Error를 발생시키고, Error는 Failure가 될 수 있는 컴포넌트의 일부이다. 덤벙대는 프로그래머(Fault)가 버그(Error)를 발생시키는 것이다. 이 Error는 Failure를 발생시키고, Failure란 컴포넌트가 명세된 일을 수행하지 못하는 것이다.
다음은 Fault를 다루는 방법이다.
- Fault Prevention(결함 예방): 결함을 예방하는 것으로, 부주의한 프로그래머를 고용하지 않는 것이다.
- Fault Tolerance(결함 허용): 결함 발생을 mask(fault를 detection)할 수 있도록 컴포넌트를 구축하는 것으로, 각 컴포넌트를 두 명의 프로그래머가 서로 피드백을 주며 개발하도록 한다.
- Fault Removal(결함 제거): 결함의 존재 수나 심각성을 줄이는 것으로, 부주의한 프로그래머를 없애는 것이다.
(..? 너무 무서운데) - Fault Forcasting(결함 예측): 현재 존재하는 결함, 미래 발생 가능성 및 그로 인한 영향을 추정하는 것으로, 채용 담당자가 부주의한 프로그래머를 얼마나 잘 걸러내고 있는지 평가한다.
Failure Models
Failure의 종류에는 여러가지가 있다.
- Crash failure: 작동이 중단(Hault)되지만, 중단되기 전까지는 정상적으로 작동한다. 그나마 괜찮은 failure이다.
- Omission failure(생략 실패): 들어오는 요청에 응답하지 못하는 것이다. Receive omission은 들어오는 메시지에 응답하지 못한 것이고, Send omission은 메시지를 보내는 것에 실패한 것이다.
- Timing failure(Performance failure): 응답이 지정된 시간 간격에 이루어지지 못한 것이다.
- Response failure: 응답이 잘못된 것이다. Value failure는 응답 값이 잘못된 것이고, Stat-transition failure는 올바른 흐름 제어에서 벗어난 것이다.
- Arbitrary failure(임의 실패): 임의의 시간에 임의의 응답을 생성할 수 있는 것이다. 쉽게 말하자면 원인을 모르는 실패로, 가장 최악의 failure이다.
Arvitrary failure는 악의적인 것으로 간주되기 때문에, 구분을 하는 것이 오히려 더 낫다.
Omission(생략)과 Commission(실행)으로 구분을 하는데, 생략 실패란 컴포넌트가 수행해야할 작업을 수행하지 않은 것이고, 실행 실패란 컴포넌트가 수행하지 말아야 할 작업을 수행한 것이다.
주의할 점은, Arvitrary failure는 일반적으로 보안 문제로 간주된다. 의도적인 실패(deliberate failure)와 비의도적인 실패(unintentional failure)는 구분이 불가능하기 때문이다.
Halting Failures (중단 실패)
C가 더 이상 C*의 활동을 감지하지 못하면, 중단 실패일까?
사실 Crash failure와 Omission/Timing failure는 구분하기 힘들다. 이 실패들은 전부 중단을 야기하기 때문이다.
비동기 시스템에서는 프로세스 실행 속도나 메시지 전달 시간에 대한 가정이 없다.
따라서 Crash failure를 신뢰성 있게 감지할 수 없다. 메시지가 사방에서 들어오고 있는데 오류를 감지하는 것은 힘들기 때문이다.
동기 시스템에서는 프로세스의 실행 속도나 메시지 전달 시간이 제한되어 있다.
따라서 Omission/Timing failure를 신뢰성 있게 감지할 수 있다.
이러한 특징들 때문에, 실무에서는 부분적으로 동기 시스템을 사용한다. 대부분의 경우 시스템이 동기적이라고 할 수 있지만, 비동기 상태일 수도 있는 시간에는 제한이 존재하지 않는다. 이 방법으로는 Crash failure를 신뢰성 있게 감지할 수 있다.
아래는 중단 종류에 대한 내용이다.
- Fail-stop: Crash failure가 발생하지만 신뢰성 있게 감지할 수 있다.
- Fail-noisy: Crash failure가 발생하지만 결국 신뢰성 있게 감지할 수 있다.
- Fail-silent: Omission 이나 Crash failure가 발생하며, 클라이언트는 어떤 문제가 발생했는지 알 수 없다.
- Fail-safe: Arbitrary failure가 발생하지만, 시스템에는 무해한 실패이다.
- Fail-arbitrary: Arbitrary failure가 발생하며, 악의적인 실패를 포함할 수 있다.
Redundancy for Failure Masking: 결함 마스킹을 위한 중복성
결함 마스킹이란, Failure를 detection하는 것이다.
다음은 중복성의 유형에 대한 내용이다.
- Informaion redundancy: 데이터 유닛에 비트를 추가하여 비트가 손상되었을 때 오류를 복구할 수 있도록 한다. 패리티 코드나 해밍코드가 이에 해당한다.
- Time redundancy: 문제가 발생했을 경우 작업을 다시 수행할 수 있도록 시스템을 설계한다. 일반적으로 일시적이거나 간헐적인 결함에 사용된다.
- Physical redundancy: 하나 이상의 구성 요소가 고장나더라도 시스템이 계속 작동할 수 있도록 장비나 프로세스를 추가한다. 분산 시스템에서는 광범위하게 사용된다.
Process Resilience: 프로세스의 회복력
프로세스 복제를 통해 오작동(malfunctioning)하는 프로세스를 보호하고, 여러 프로세스를 그룹으로 조직한다.
평면 그룹과 계층적 그룹으로 구분할 수 있다.
평면 그룹(Flat group)은 모든 프로세스가 평등하게 제어를 분담하며, 완전히 분산된 제어 구조를 가지므로 구현이 어렵고 더 많은 오버헤드를 유발할 수 있다.
계층적 그룹(Hierarchical group)은 상대적으로 구현이 쉽지만, 완전한 장애 내성이나 확장성은 갖추지 못할 수 있다. 위 그림에서는 Coordinator가 Single-point-of-failure로, coordinator 노드 하나가 고장나면 실패한다는 것이다.
Groups and Failure Masking: 그룹과 결합 마스킹
그룹이 k concurrent member failures를 마스킹할 수 있을 때, 이를 k-fault tolerant group 이라고 한다. 여기서 k는 결함 허용 정도라고 한다.
그렇다면 k-fault tolerant group의 크기는 얼만큼 커야할까?
- 중단 실패(Crush/Omission/Timing failure)인 경우, k개의 구성원 결함에서 생존하려면 k+1 개의 구성원이 필요하다.
- 임의의 실패인 경우, k개의 구성원 결함에서 생존하려면 2k + 1개의 구성원이 필요하며, 올바른 결과를 얻기 위해 다수결을 통해 결정하도록 한다.
여기서 모든 구성원은 동일하며, 모든 구성원이 명령을 동일한 순서로 처리하는 가정이 존재한다. 이러한 조건이 만족된다면, 모든 프로세스가 정확히 동일한 작업을 수행한다고 할 수 있다.
만약 그룹 구성원이 동일하지 않은 경우, 오류가 없는 그룹 구성원들은 동일한 값에 대해 합의를 해야한다.
색칠되어 있는 노드가 오류를 발생시키는 노드이다.
(a)에서는 P3가 a와 b 두개의 값을 받아 다른 값을 전달할 수 있고, (b)는 P2가 애초에 잘못된 값을 받아 전달한다.
Atbitraty failure smantics(임의의 실패 의미론)을 가정할 경우, k개의 결함이 있는 구성원들의 공격에 대응하기 위해 3k+1개의 그룹 구성원이 필요하다. 이는 Byzantine failures라고 알려져 있으며, k개의 배신자가 존재하는 상황에서, 3k+1의 구성원들 사이에서 다수결을 시도하려면 2k+1명의 충성스러운 구성원이 필요하다.
Consensus nuder Arbitrary Failure Semantics: 임의의 실패 의미론 하에서의 합의
시스템은 프라이머리 P와 n-1개의 백업 프로세스 $B_1, ... B_{n-1}$를 고려하고, 클라이언트 v가 T나 F를 P로 보낸다.
메시지는 손실될 수 있지만 감지가 가능하고, 메시지가 감지 불가능 수준으로 손상되지는 않는다. 메시지의 수신자는 신뢰성있게 발신자를 감지할 수 있다.
다음은 바잔틴 합의의 요구사항이다.
- BA1 - 모든 비결함 백업 프로세스는 동일한 값을 저장해야한다.
- BA2 - 프라이머리가 비결함 상태인 경우, 모든 비결함 백업 프로세스는 프라이머리가 보낸 값을 정확히 저장해야한다.
프라이머리가 결함인 경우, BA1은 만족되지만 클라이언트가 보낸 원래 값과는 다른 값을 저장할 수 있다.
프라이머리가 비결함인 경우, BA2가 만족되고 자동으로 BA1도 만족한다.
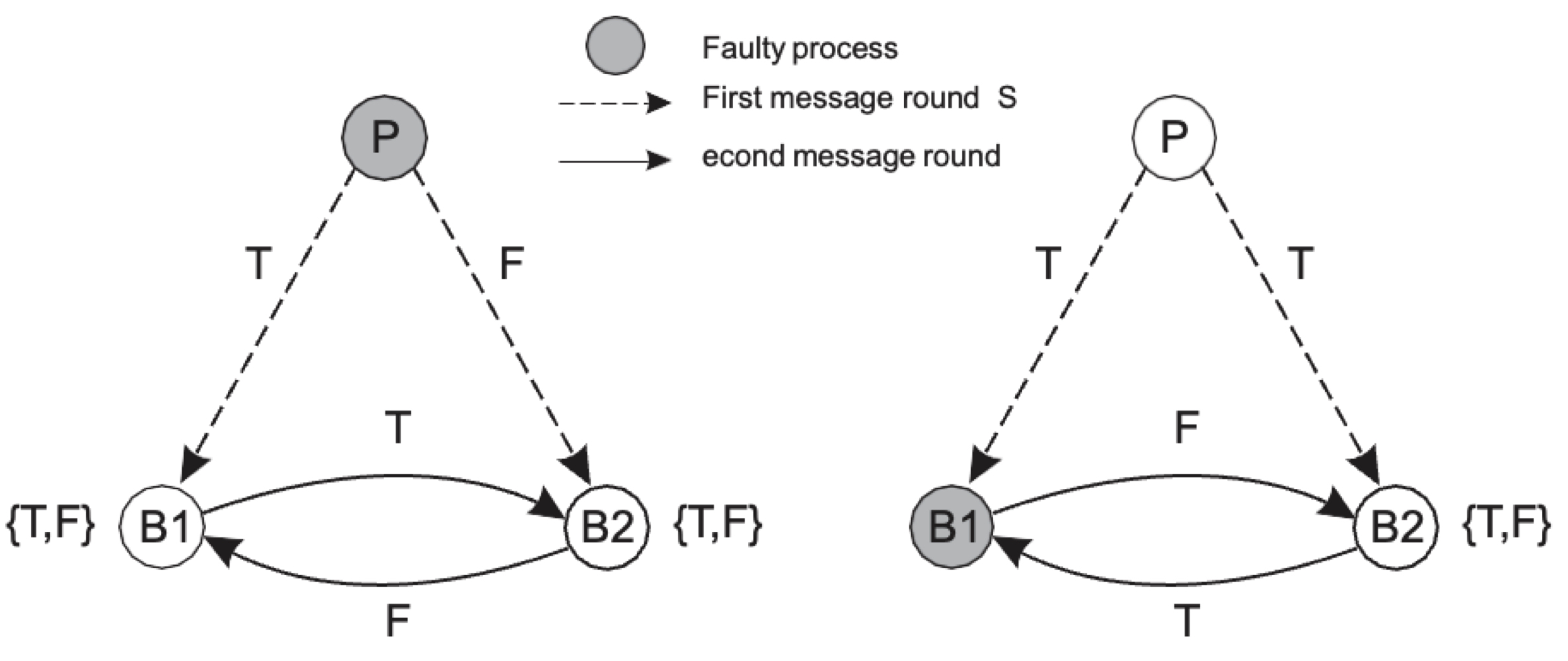
노드가 3k개일 때는, 다수결을 진행하지 못한다. 위 그림에서는 k=1일 때의 상황을 나타낸다.
결함이 있는 P가 B1에게 T를, B2에게 F를 보냈다. 동기화를 위해 B1과 B2가 서로 값을 주고 받았는데, 각각 {T, F}의 값만을 갖게 되었을 뿐 값을 하나로 결정하지 못한다. B1에 결함이 있을 때도 마찬가지다.
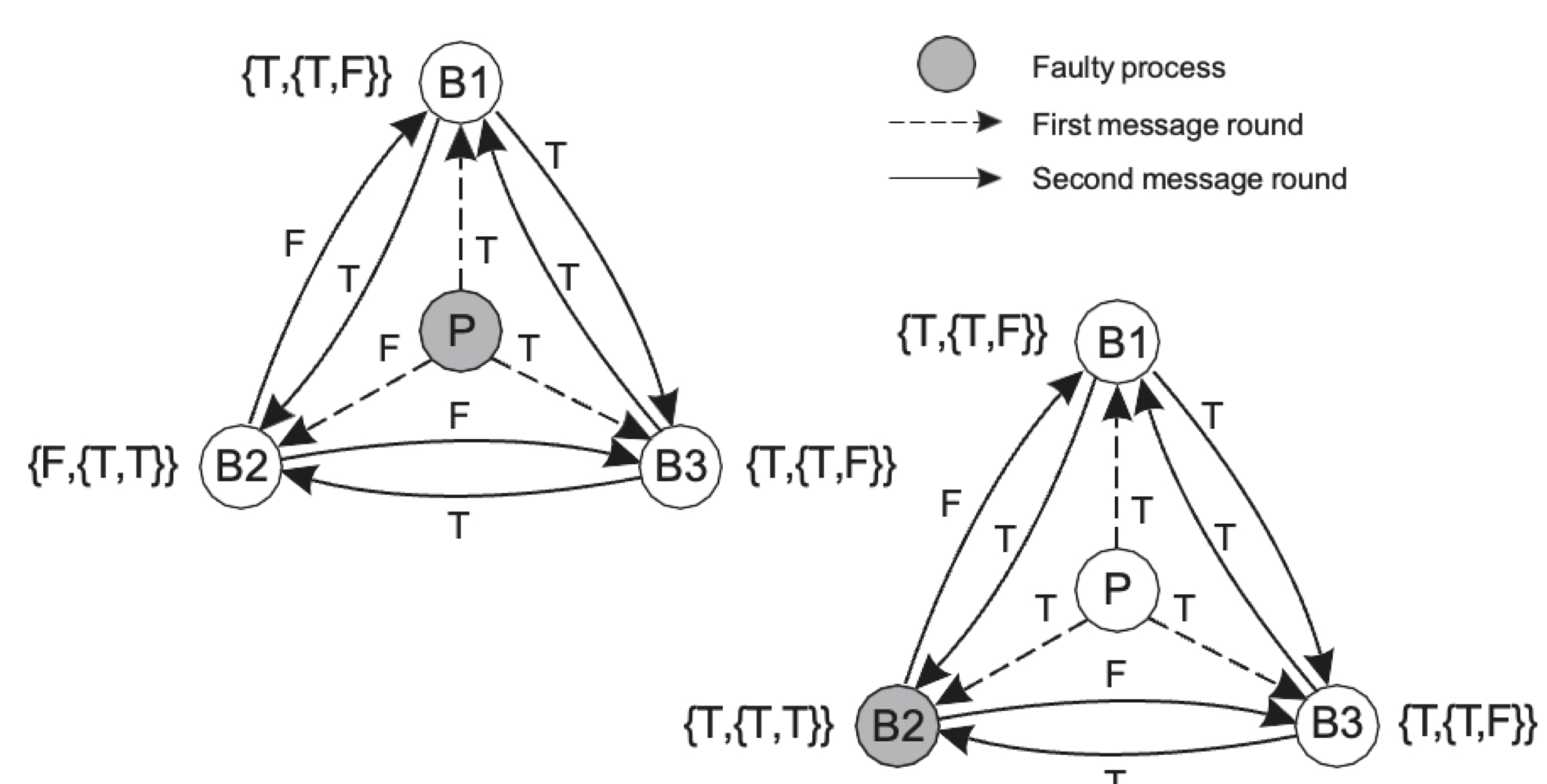
노드가 3k+1일 때는 비로소 다수결을 진행할 수 있다.
결함이 있는 P가 B1, B3에는 T를 보내고 B2에는 F를 보냈다. 각 백업 노드가 값을 교환하니, {T, T, F}의 값을 가지게 되었고 이는 다수결로 인해 T의 값이 저장된다. B2에 결함이 있을 때도 마찬가지로 다수결이 가능하다.
** 대학교 수업을 듣고 이해한 부분을 최대한 풀어서 작성한 글입니다.
틀린 정보가 존재할 수 있으며, 언제나 피드백은 환영입니다. **
'DKU > 분산처리' 카테고리의 다른 글
| Distributed System 16 (1) | 2024.12.13 |
|---|---|
| Distributed System 15 (1) | 2024.11.21 |
| Distributed System 13 (2) | 2024.11.11 |
| Distributed System 12 (0) | 2024.11.05 |
| Distributed System 11 (0) | 2024.11.05 |