
Fault Tolerance 이어서
Consensus: 합의
하나 이상의 시스템이 값을 제안할 때, 시스템들이 어떻게 합의하여 하나의 값을 결정할까?
전제 조건(Prerequisite)이 있는데, 결함 허용 프로세스 그룹에서는 모든 비결함 프로세스가 다른 비결함 프로세스와 동일한 명령을 동일한 순서로 실행해야된다는 것이다. 이 말은, 비결함 그룹 구성원들은 다음에 실행할 명령에 대해 합의해야된다는 것이다.
Flooding-based Consensus
시스템에는 프로세스 그룹 P = {$P_1, ... P_n$}이 있고, Fail-stop 실패 의미론(신뢰할 수 있는 실패 감지 기능)을 가정한다. 클라이언트가 특정 프로세스 $P_i$에 접촉하여 명령 실행을 요청하면, 모든 $P_i$는 제안된 명령 목록을 유지한다.
다음은 이 합의에서 사용되는 라운드 기반의 기본 알고리즘 작동 방식이다.
- 라운드 r 에서: 프로세스 $P_i$는 자신이 알고 있는 명령 집합 $C^i_r$를 다른 모든 프로세스들에게 멀티캐스트한다.
- 라운드 r 종료 시: 각 프로세스 $P_i$는 수신된 모든 명령을 병합하여 새로운 명령 집합 $C^i_{r+1}$을 만든다.
- 다음 명령 선택: 다음 명령 $cmd_i$는 전역적으로 공유된 결정적 함수에 의해 선택된다.

위 그림에서 프로세스 $P_2$는 다른 모든 프로세스들로부터 제안된 모든 명령을 수신하고 결정을 내릴 수 있다.
프로세스 $P_3$는 $P_1$이 충돌한 것을 감지할 수 있지만, $P_2$가 $P_1$으로부터 어떤 정보를 받았는지 알 수 없다. 즉, $P_3$는 자신이 $P_2$와 동일한 정보를 가졌는지 알 수 없기 때문에 결정을 내릴 수 없다. $P_4$도 같은 이유로 결정을 내릴 수 없다.
Paxos
Paxos는 비동기 네트워크를 통해 통신하는 분산된 시스템 집합에서 합의를 이루기 위해 사용되는 알고리즘이다.
하나 이상의 클라이언트가 Paxos에 값을 제안할 수 있으며, Paxos를 실행하는 여러 시스템이 제안된 값 중 하나에 대해 합의를 한다.
간단하게 먼저 설명하자면, Paxos는 제안된 값 중 단일 값을 선택하고, 이 값을 모든 참여자에게 알려주는 방식으로 작동한다.
Paxos 프로토콜의 실행은 단일 제안된 값을 선택하는 것으로 끝나며, 만약 Paxos를 사용해서 복제 로그를 생성해야하는 경우에는 여러 번 반복해서 Paxos를 실행해야한다.
다음은 Paxos 알고리즘의 가정이다.
- Concourrent proposals(동시 제안): 하나 이상의 시스템이 동시에 값을 제안할 수 있다.
- Validity(유효성): 합의로 선택된 값은 반드시 제안된 값 중 하나여야 한다.
- Majority rule(다수결 규칙): Paxos 서버의 과반수가 하나의 값에 동의하면, 그 값에 대한 합의가 이루어진다.
- Asynchornous network(비동기 네트워크): 네트워크는 신뢰할 수 없고 비동기적으로 동작한다. 메시지는 손실되거나 임의로 지연될 수 있으며, 네트워크는 분할될 수 있다.
- Fail-stop faults(실패 중단 결함): 시스템은 fail-stop faults를 보일 수 있다. 이 경우 시스템이 멈출 수 있지만, 재시작할 때 이전 상태를 기억하여 결정을 번복하지 않도록 해야한다. 이러한 결함은 비잔틴 결함이 아니므로, 임의의 잘못된 동작이나 악의적인 행동은 포함되지 않는다.
- Unicasts(유니캐스트 통신): 통신은 point-to-point방식으로 이루어진다. Paxos서버 집합에 메시지를 원자적으로 멀티캐스트하는 메커니즘은 없다.
- Announcement(알림): 합의에 도달하면 그 결과는 모든 참여자들에게 알려질 수 있다.
Paxos에는 세 가지 주요 엔터티가 있다.
- Proposers(제안자): 클라이언트로부터 요청(값)을 받아서 이를 acceptors에게 제안하고, 해당 값을 수락하도록 설득한다.
- Acceptors(수락자): proposers로부터 제안된 특정 값을 수락하고, 다른 값이 이미 수락된 경우 제안자에게 이를 알린다. acceptor에 대한 응답은 특정 제안에 대한 투표를 의미한다.
- Learners(학습자): 합의의 결과를 발표하는 역할이다.
하나의 노드는 proposer, acceptor, learner의 역할을 동시에 수행할 수 있다.
클라이언트는 Paxos 프로토콜의 proposers 중 하나에 요청을 보낸다. proposers는 acceptors와 함께 두 단계의 프로토콜을 실행한다.
Paxos는 다수결 기반 프로토콜로, 다수결을 통해 합의를 이루며, 다수결은 split-brain 문제를 방지한다. Paxos 알고리즘이 종료되기 위해서는 과반수의 노드가 실행 중이여야 한다.
다수결은 한 다수 집합과 다른 다수 집합에 최소 하나의 공통 노드가 존재함을 보장하기 때문에, 서버가 종료되고 재시작하더라도 일관성을 유지할 수 있다. 시스템에는 2k+1개의 노드가 있어야 k개의 결함을 허용할 수 있다.
Paxos는 합의를 이루기 위해 다수의 acceptors가 필요하다. proposers와 learners는 한개 보다 더 적어도 된다.
acceptors는 수락한 값을 잊어서는 안되므로, proposers로부터 수신한 정보를 안정적인 장소에 기록하여 추적해야한다. 즉, 저장된 내용은 프로세스가 재시작되더라도 복원될 수 있어야한다.
자, 그럼 이제 Paxos 알고리즘의 두 단계 프로토콜에 대해 알아보겠다.
- Phase1: proposers는 모든 작동 중인 acceptors에게 이미 제안을 받은 적이 있는지 묻는다. 만약 아니라면, proposers는 새로운 값을 제안한다.
- Phase2: 다수의 acceptors들이 제안된 값에 동의하면, 해당 값이 합의된 것이다.
여기서 각 제안에는 고유한 번호가 부여된다. 더 높은 제한 번호는 낮은 번호보다 우선권을 갖게 되며, proposers는 자신이 이전에 사용한 모든 번호보다 높은 제안 번호를 선택할 수 있어야한다.
각 서버가 자신이 본 가장 큰 Round Number를 maxRound로 저장한다고 했을 때, 새로운 제안 번호를 생성시키려면 maxRound를 증가시키고 이를 Server ID와 연결하여 새로운 제안 번호를 생성한다. proposers는 maxRound를 안정적인 저장소에 지속적으로 저장해야 하며, 시스템이 충돌하거나 재시작한 후에도 제안 번호를 재사용해서는 안된다.
Paxos가 어떻게 작동하는지 보자.
Proposer는 각 acceptor 에게 "Prepare request(준비요청)"을 보낸다.
Proposer A의 요청은 Acceptor X와 Y에 먼저 도착하고, Proposer B의 요청은 Acceptor Z에 먼저 도착한다.
Acceptor들이 준비 요청을 받은 적이 없다면, 각 Proposer에게 응답을 보낸다.
Acceptor X와 Y는 Proposer A에게 "Prepare response(준비 응답)"을 보내고, Acceptor Z는 Proposer B에게 준비 응답을 보낸다.
Acceptor가 준비 요청을 이미 받은 경우, 제안 번호(N)와 값(V)을 포함한 응답을 각 Proposer에게 보낸다.
Acceptor X와 Y는 Proposer B에게 준비 응답을 보내고, Acceptor Z는 Proposer A의 요청을 무시한다. 여기서 Acceptor Z가 무시하는 이유는, Acceptor Z가 이미 처리한 Proposer B의 n=4보다 Propser A의 n=2이 작기 때문이다. Paxos에서는 자신이 이미 처리한 요청보다 작은 번호의 요청에 대해서는 응답하지 않도록 설계되어 있다.
우선순위가 더 높은 Proposer B가 "Accept request(승인 요청)"을 Aceeptor X, Y, Z에게 보낸다.
[n=2, v=8]이 [n=4, v=8]로 바뀐다. 제안 번호가 클 수록 우선순위가 더 높기 때문에 제안 번호가 업데이트 된 것이고, v=8은 이미 다수결로 합의된 값이므로 그대로 유지된다. Paxos에서는 새로운 제안 번호로 요청을 보낼 때도, 이미 합의된 값이 있으면 이를 유지하는 것이 규칙이다.
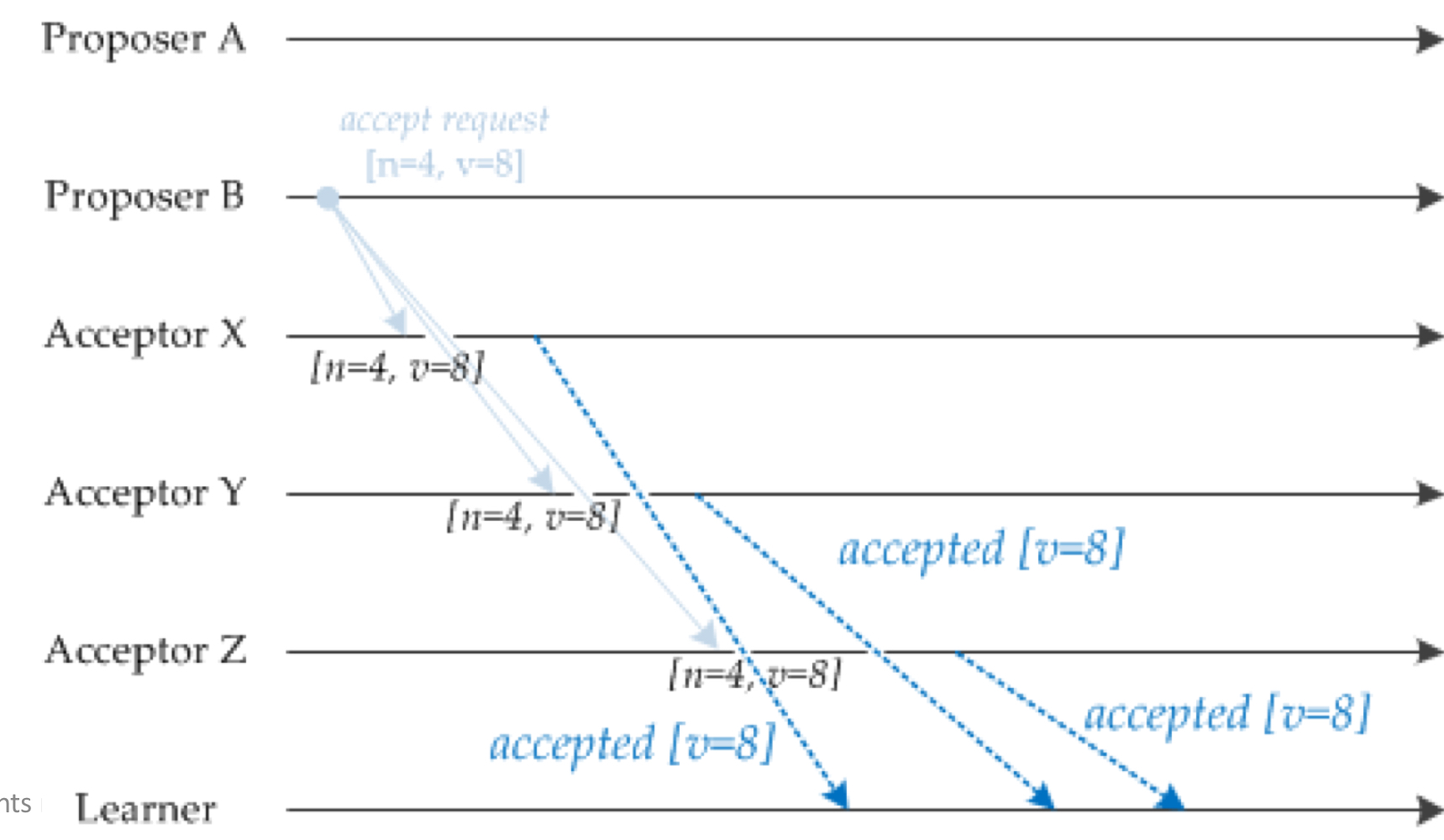
Acceptor들이 승인 요청을 받으면, Learner에게 "accepted(승인됨)"을 보낸다.
만약 Proposer C가 제안번호 n=6과 값 v=7로 prepare request를 보낸다면, Acceptor는 현재의 값 [n=4, v=8]을 prepare response로 반환한다. 이후 Proposer C는 기존 값을 유지한 채, 더 높은 번호[n=6, v=8]의 accept request를 보낸다. Acceptor는 이를 수락하고 Proposal C를 승인한다.
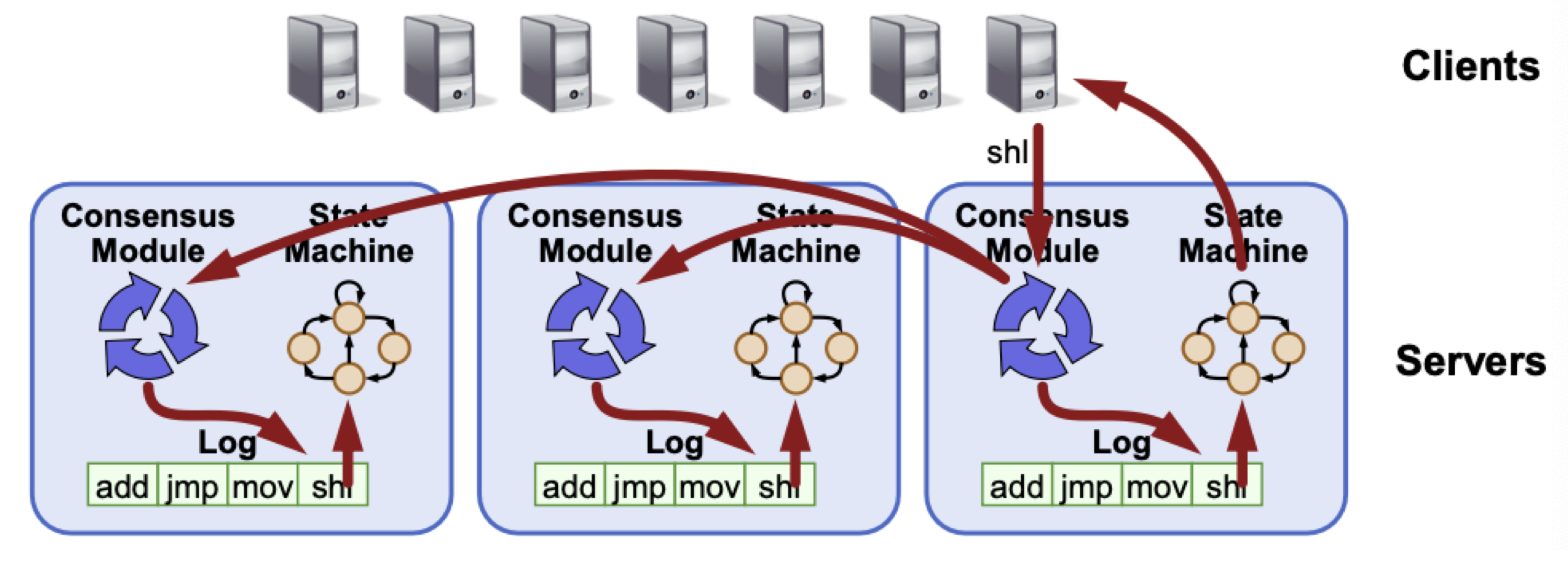
복제된 로그는 모든 서버에 동일하게 복제된 로그를 유지하는 것을 의미한다.
이 로그를 기반으로 복제된 상태 기계는 각 서버가 동일한 명령어를 순서대로 실행함으로써 일관된 상태를 유지한다.
Multi-Paxos는 여러 인스턴스의 기본 Paxos를 결합하여, 일련의 log에 대해 합의하도록 확장한 프로토콜이다.
클라이언트가 서버로 명령어를 보내면, 서버는 Paxos를 사용해 log의 값으로 사용될 명령어를 고른다. 서버는 우선순위가 높은 log들이 처리되기를 기다리고, 상태 기계에 새로운 명령어를 제공한다. 서버는 상태 기계로부터 나온 결과를 클라이언트에게 반환한다.
Raft
Raft는 Paxos의 단순화 버전으로, 보다 이해하기 쉽도록 설계되었다. Raft는 leader election(리더 선출)과 log propagation(로그 전파)로 분리할 수 있다. 리더가 선출되면, 리더가 모든 결정을 내리며 이를 순서화된 로그를 통해 다른 노드들에게 전달한다.
Raft에서 노드가 가질 수 있는 상태는 Leader, Follower, Candidate으로 총 세 가지다.
- Leader: 리더로 선출된 서버만 클라이언트와 상호작용이 가능하며, 다른 모든 서버는 리더와 동기화하여 데이터를 맞춘다. 리더는 최대 한 대만 존재할 수 있다.
- Follower: 팔로워 서버는 일정한 시간 간격으로 리더의 데이터를 복사해 자신의 데이터를 동기화한다. 리더 서버가 다운되면, 팔로워 중 하나가 리더 선출을 위한 선거에 참여하여 리더가 될 수 있다.
- Candidate(후보자): 리더 서버를 선출하는 선거에 참여할 때, 후보자 서버가 다른 서버들에게 투표를 요청할 수 있다.
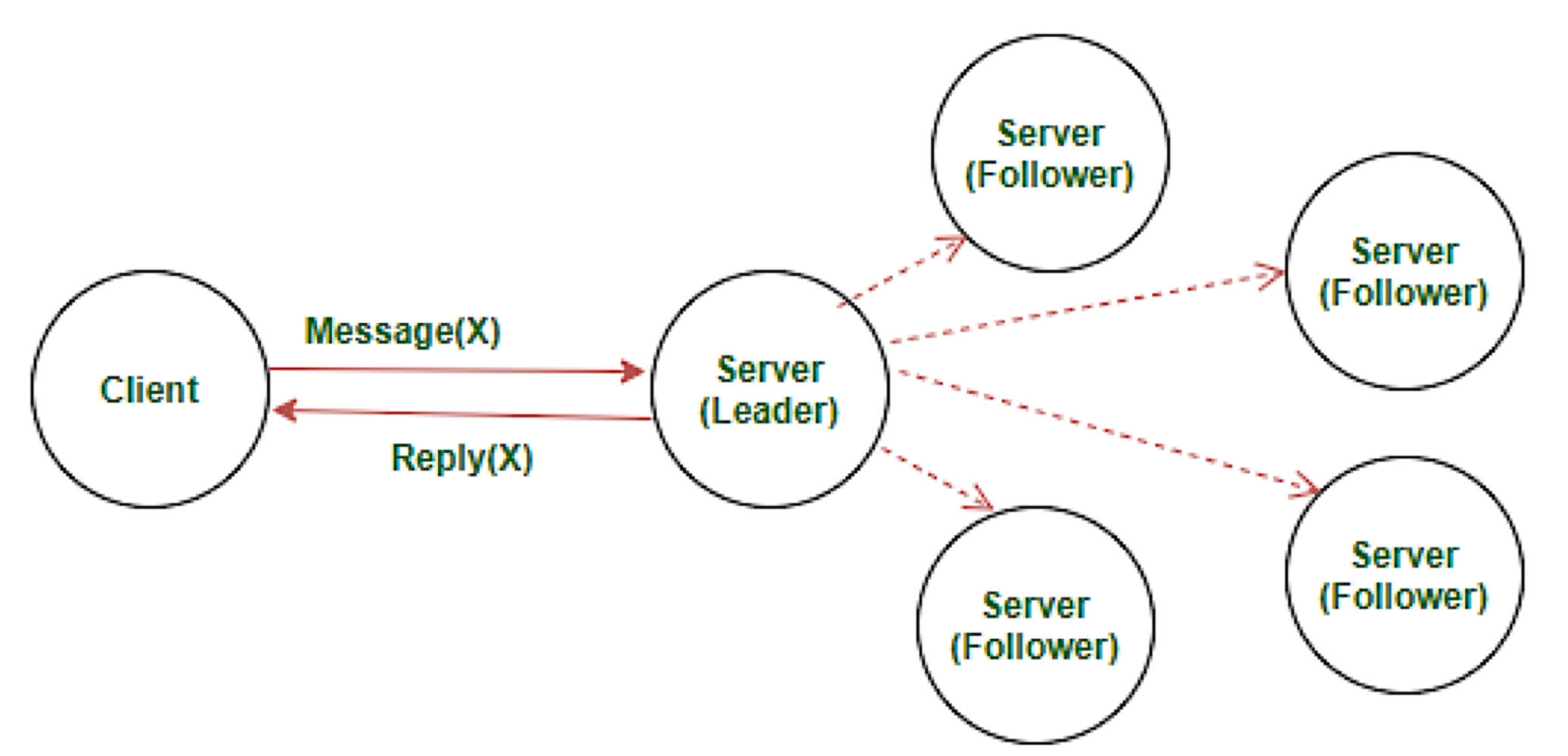
Raft에서 시간은 Term(임기)로 나누어진다.
Term에는 단조롭게 증가하는 번호가 있으며, 각 Term은 선거로 시작한다.
선거에서는 하나 이상의 후보가 리더가 되길 시도하고, 선거에서 승리한 후보가 해당 Term의 나머지 기간 동안 리더로 활동한다.
Term은 오래된 정보를 감지하는데 사용된다. 각 서버는 현재 term을 저장하고, 모든 요청에서 현재 trem이 확인된다. 여기서 trem을 저장하고 확인하는건, 번호를 본다는 것이다. 서로 다른 서버는 term의 전환을 다르게 관찰할 수 있다.
서버 간 요청-응답 프로토콜에는 RequestVote와 AppendEntries(항목추가, 하트비트 역할)이 있다.
리더 선출은 어떻게 이루어지는지 살펴보자.
일단, 모든 서버는 팔로워 상태에서 시작한다. 어느 한 서버가 하트비트를 받지 못하면(타임아웃이 되면) 선거를 시작하게 된다. 선거를 시작하려는 서버의 Term을 증가시키고, 다른 모든 서버에게 RequestVote 요청을 보낸다.
클러스터의 과반수로부터 투표를 받으면 리더가 되고, 추가 선거를 방지하기 위해 리더가 된 서버는 하트비트를 전송한다. 새로운 Term에서 다른 서버들은 AppendEntries(하트비트)를 받으면 팔로워로 돌아간다(타임아웃이 초기화 된다.). 어느 한 서버에서 타임아웃이 발생하면, 새로운 선거를 시작하게 된다.
각 서버는 주어진 Trem에서 최대 한 명의 후보에게만 투표가 가능하며, 주어진 Term에서 단 하나의 서버만 리더로 선출될 수 있다. 랜덤화된 타임아웃을 통해 투표 분열을 줄일 수 있다. 랜덤화된 타임아웃은, 동시 선거가 발생할 확률을 낮춰준다.
로그 복제는 어떻게 이루어지는지 살펴보자.
로그 복제는 리더가 처리하며, 클라이언트의 요청이 도착하면 리더의 로컬 로그에 추가하고 AppendEntries 요청을 사용해 다른 서버들에 복제한다. 리더가 해당 항목(entry)을 과반수의 서버에 복제하면 committed(커밋) 상태가 되는데, 커밋된 항목을 로컬 상태 기계에 적용한다. 클라이언트에게 결과를 반환해주고, AppendEntries 요청에서 다른 서버들에게 커밋된 항목을 알린다.
여기서 로그 항목의 구성요소는 인덱스, 임기, 명령이다.
리더가 다운되면 일부 로그가 복제되지 않아 로그의 불일치가 생길 수 있다.
Raft는 높은 수준의 로그 일관성을 유지한다. 서로 다른 로그에서 같은 임기와 인덱스를 가진 항목은 반드시 동일한 명령을 가지기 때문에 해당 entry 까지는 두 로그가 동일하다. 리더는 다른 로그를 자신의 로그와 일치하도록 강제한다. 팔로워별 nextIndex를 유지하고, AppendEntries 요청 시 실패하면 해당 팔로워의 nextIndex를 감소시킨 뒤에 다시 시도한다. 팔로워가 충돌 항목(conflicting entry)을 받았을 때, 일관성 검사를 통과하면 충돌하는 항목을 모두 제거한다.
분산처리 과목은 번역하기 시작하면 이해하기가 너무 어려워진다.
시험공부는 용어의 의미를 잘 정리한 뒤에 시작하는 것이 좋겠다.
** 대학교 수업을 듣고 이해한 부분을 최대한 풀어서 작성한 글입니다.
틀린 정보가 존재할 수 있으며, 언제나 피드백은 환영입니다. **
'DKU > 분산처리' 카테고리의 다른 글
| Distributed System 17 (0) | 2024.12.14 |
|---|---|
| Distributed System 16 (1) | 2024.12.13 |
| Distributed System 14 (1) | 2024.11.18 |
| Distributed System 13 (2) | 2024.11.11 |
| Distributed System 12 (0) | 2024.11.05 |