
Fault Tolerance 이어서
Failure Detection: 오류 감지
프로세스가 실제로 충돌했는지를 신뢰성 있게 감지하는 방법
- 일반적인 모델: 각 프로세스는 장애 감지 모듈을 장착하고 있으며, 프로세스 P가 다른 프로세스 Q 반응을 요청한다. Q가 반응하면, P는 Q가 살아있다고 간주하며, Q가 t 시간 내에 반응하지 않으면, P는 Q가 충돌했다고 의심한다.
- 실질적인 구현: P가 t 시간 내에 Q로부터 heartbeat(정기적인 상태 확인 메시지)을 받지 못하면, P는 Q를 의심한다. 이후 Q가 P에게 메시지를 보내면, P는 Q에 대한 의심을 멈추며 P는 timeout 값 t를 늘린다. Q가 실제로 충돌했다면, P는 Q에 대한 의심을 계속 유지한다.
Reliable Remote Procedure Calls: 신뢰할 수 있는 원격 프로시저 호출
문제가 발생할 수 있는 상황에는 다음과 같은 경우가 있다.
- 클라이언트가 서버를 찾을 수 없다.
- 클라이언트에서 서버로 보내는 요청 메시지가 손실된다.
- 서버가 요청을 받은 후에 충돌한다.
- 서버가 클라이언트로 보내는 응답 메시지가 손실된다.
- 클라이언트가 요청을 보낸 후에 충돌한다.
간단한 해결책으로는,
- 서버를 찾을 수 없는 경우, 클라이언트에게 보고(report)만 한다.
- 요청 메시지가 손실된 경우, 메시지를 다시 보낸다.
Reliable RPC: Server Crash

(a)가 보통 케이스고, (b), (c)와 같은 상황은 서로 다른 해결책이 필요하지만, 실제로 무엇이 발생했는지 알 수 없다.
- 최소 1회 실행 의미론(At-least-once semantics): 서버는 어떤 상황에서도 작업을 최소한 한 번을 수행할 것을 보장한다.
- 최대 1회 실행 의미론(At-most-once semantics): 서버는 작업을 최대 한 번만 수행할 것을 보장한다.
왜 Fully Transparent Server Recovery는 불가능한 걸까?
일단, 서버에서 발생할 수 있는 세 가지 유형의 이벤트에는 3가지가 있다. (문서를 업데이트하는 작업)
- M: 완료 메시지를 전송한다.
- P: 문서 처리를 완료한다.
- C: 서버가 충돌한다.
이 이벤트에 따라 발생가능한 6가지 경우가 있다.
- M - P - C: 완료를 보고한 후에 충돌했다. 이 경우 문서를 업데이트하는 작업에는 문제가 없다.
- M - C - (P): 완료를 보고했으나 업데이트 전 충돌했다.
- P - M - C: 업데이트를 완료하고 보고한 후 충돌했다. 이 경우도 문제는 없다.
- P - C - (M): 업데이트가 완료되었으나 보고하지 못하고 충돌했다.
- C - (P - M): 아무것도 수행하지 못하고 충돌했다.
- C - (M - P): 아무것도 수행하지 못하고 충돌했다.
Reissue strategy: 재전송 전략
- Always: 항상 요청을 재전송
- Never: 요청을 절대 재전송하지 않는다.
- Only when ACKed: M이 수행되었을 때만 재전송
- Only when not ACKed: M이 수행되지 않았을 때만 재전송
Reliable RPC: Lost Relpy Messages
RPC에서 문제가 발생했을 때, 클라이언트가 알 수 있는 건 응답을 받지 못했다는 사실 뿐이다. 이는 요청 메시지 손실, 서버 충돌, 응답 메시지 손실 중 어떤 원인으로 발생했는지 판단할 수 없다.
따라서, 서버는 작업을 멱등성(idempotent)을 가지도록 설계해야 한다. 멱등성이란, 동일한 작업을 반복 실행해도, 한 번만 수행한 것과 동일한 결과를 보장하는 것이다.
- Pure read operations: 데이터 읽기 작업은 여러 번 실행해도 결과가 변하지 않는다. 멱등성을 가지고 있는 것이다.
- Strict overwirte operations: 데이터를 특정 값으로 덮어쓰는 작업 역시 결과가 변하지 않으며, 멱등성을 가지고 있다.
- Non-idempotent operations: 예를 들어, 은행 거래(banking transcations)는 동일한 작업을 반복하면 결과가 달라진다.(이체 또는 결제)
Reliable RPC: Client Crash
이 경우에, 서버는 불필요한 작업을 수행하고 리소스를 점유하게 된다. 이를 고아 계산(ophan computation)이라고 한다.
해결책은 다음과 같다.
- 클라이언트가 복구되면 클라이언트에 의해 고아를 종료하거나 롤백시킨다.
- 클라이언트가 복구되었을 때, 새로운 epoch 번호를 브로드캐스트한다. 서버는 클라이언트의 고아를 종료한다.
- 작업은 반드시 T시간 내에 완료되도록 강제한다. T시간 이후의 오래된 작업은 제거된다.
Simple Reliable Group Communication
직관적으로, 프로세스 그룹 G에 메시지를 전송하면 그룹 G의 모든 멤버에게 메시지가 전달되어야한다. 메시지를 수신(receving)하는 것과 전달(delivering)하는 것에 차이를 두면 된다.
P가 요청을 순차적으로 보낸다. B1에 요청을 보낸 후에, 응답을 받을 때까지 다음 프로세스에 요청을 보내지 않는다. B1에게 응답을 받으면, 그제서야 B2에게 요청을 보낸다.
안정적이고, 동기적인 방법이지만 느린 것이 단점이다.
요청은 병렬로 전송되며, P는 들어오는 응답을 기다린다.
이 방법은 그룹 멤버들의 합의를 무시하며, 안정적인 전송 프로토콜(e.g., TCP)을 배포해야한다.
신뢰 가능한 그룹 통신은 이제 신뢰 가능한 멀티캐스팅으로 귀결되며, 이는 송신자가 의도한 대로 각 수신자에게 메시지가 수신되고 전달되는 것을 의미한다.
Distributed Commit Protocols
프로세스 그룹에 분산된 계산이 있을 때, 어떻게 모든 프로세스가 최종 결과에 대해 커밋하거나, 아무도 커밋하지 않게(atomicity) 보장할 수 있을까?
Two-phase Commit Protocol(2PC)
계산을 시작한 클라이언트는 조정자(coordinator)로 동작하며, 커밋이 필요한 프로세스들은 참여자(participants)로 동작한다.
- phase 1a: 조정자가 참여자들에게 VOTE-REQUEST를 전송한다. (pre-write라고도 한다.)
- phase 1b: 참여자는 VOTE-REQUEST를 수신하면, VOTE-COMMIT 또는 VOTE-ABORT을 조정자에게 전송한다. 만약 VOTE-ABORT를 전송한다면, 로컬 계산을 중단한다.
- phase 2a: 조정자는 모든 투표를 수집한다. 모든 투표가 VOTE-COMMIT인 경우, GLOBAL-COMMIT을 모든 참여자에게 전송한다. 그렇지 않으면, GLOBAL-ABORT를 전송한다.
- phase 2b: 각 참여자는 GLOBAL-COMMIT 또는 GLOBAL-ABORT를 기다리고 이에 따라 처리가 진행된다.
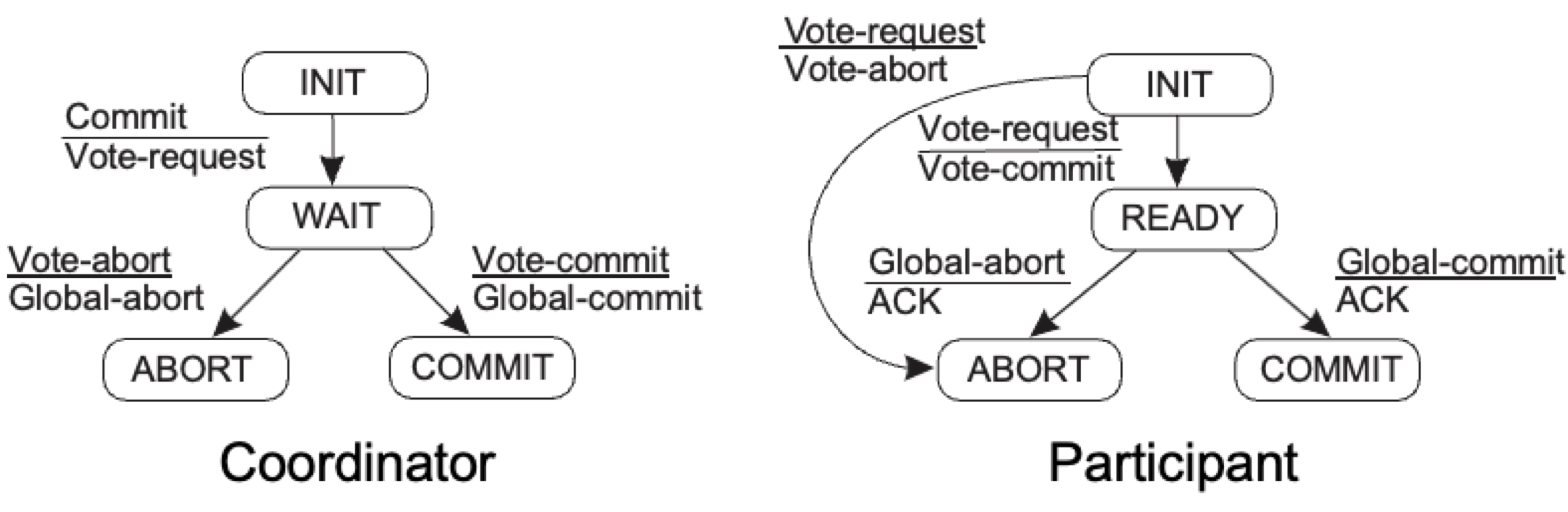
2PC - Failing Prticipant
상태 S에서 참여자가 충돌한 후, S로 다시 복구 되는 경우를 참여자 실패라고 한다.
- INIT 상태: 문제가 없다. 참여자는 프로토콜에 대해 알지 못했다.
- READY 상태: 참여자는 커밋 또는 중단을 기다리는 중이다. 복구 후에는, 어떤 상태 전환을 해야할지 알아야한다. 이를 위해, 조정자의 결과를 로그에 기록해야한다.
- ABORT 상태: 중단 상태로의 진입을 멱등하게 만들어야한다. (e.g., workspace를 제거한다.)
- COMMIT 상태: 커밋 상태로의 진입을 멱등하게 만들어야한다. (e.g., workspace를 스토리지에 복사한다.)
이처럼 분산 커밋이 필요한 경우, 참여자들이 임시 작업 영역(temporary workspace)을 사용하여 결과를 저장하면 실패 상황에서도 간단히 복구가 가능하다.
2PC - Failing Coordinator
조정자의 최종 결정(GLOBAL)이 일정시간 제공되지 않을 수 있다.
참여자 P가 READY 상태에서 조정자의 결정을 기다리다가 타임아웃이 발생하면, 다른 참여자들에게 조정자의 결정을 확인하려고 시도한다. 복구 중인 참여자는 로컬 결정을 내릴 수 없으며, 다른 프로세스들에게 의존하게 되는데 이들 역시 실패했을 가능성이 높다.
이는 2PC 프로토콜이 가지는 본질적인 한계 중 하나로, 조정자가 실패했을 때 복구의 복잡성을 증가시킨다.
Three-phase Commit Protocol(3PC)
- phase 1a: 조정자는 VOTE_REQUEST를 참여자들에게 전송한다.
- phase 1b: 참여자들이 VOTE_REQUEST를 수신하면 VOTE_COMMIT 또는 VOTE_ABORT를 반환한다. 만약 VOTE_ABORT를 전송한다면, 로컬 계산을 중단한다.
- phase 2a: 조정자는 모든 투표를 수집한다. 모든 투표가 VOTE_COMMIT인 경우, PREPARE_COMMIT을 모든 참여자에게 전송하고, 그렇지 않은 경우 GLOBAL_ABORT를 전송하고 중단한다.
- phase 2b: 각 참여자들은 PREPARE_COMMIT을 기다리거나 중단한 후 GLOBAL_ABORT를 기다린다.
- phase 3a: (커밋 준비) 조정자는 모든 참여자가 PREPARE_COMMIT을 수신하고 ACK을 반환할 때까지 대기한 후, GLOBAL_COMMIT을 모든 참여자에게 전송한다.
- phase 3b: (커밋 준비) 참여자는 GLOBAL_COMMIT을 기다리고 이에 따라 처리를 진행한다.
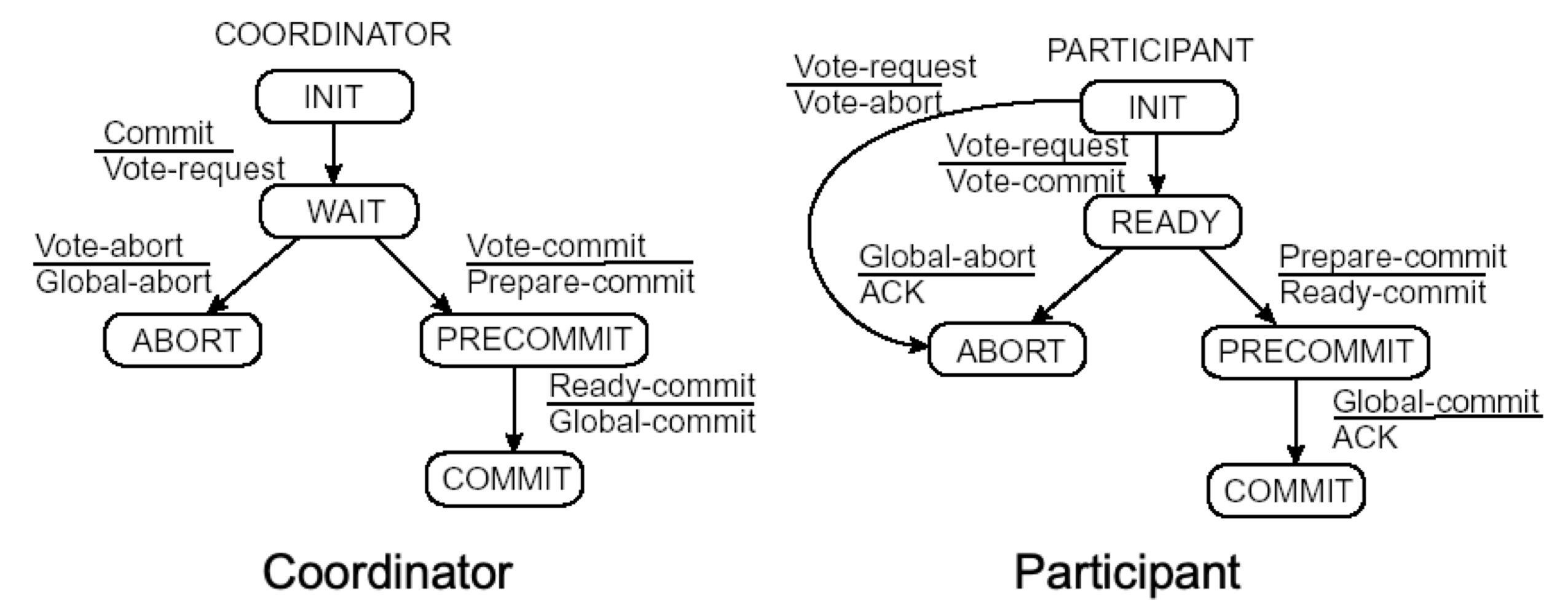
3PC - Failing Participate
참여자 P가 READY 또는 PRE-COMMIT 상태에서 충돌한 후, 다른 참여자나 조정자가 실패했더라도 자신이 무엇을 해야하는지 알 수 있는가?
조정자와 참여자는 커밋으로 가는 과정에서 항상 최대 한번의 상태 전환 차이만 가진다. 이는 상태가 불일치하면 잘못된 커밋이 발생할 수 있으므로, 모든 프로세스가 같은 상태에 있거나 다음 상태로만 이동할 수 있도록 제한한다.
참여자가 READY 상태에서 타임아웃이 발생하면, 조정자나 다른 참여자들에게 확인하여 중단해야할 지, PRE-COMMIT 상태로 전환해야하는지 알 수 있다.
참여자가 이미 PRE-COMMIT 상태에 있다면, 언제든 안전하게 커밋을 할 수 있다. (다만, 다른 프로세스에 실패를 초래하지 않도록 커밋은 허용되지 않는다.)
Recovery
실패가 발생했을 때, 시스템을 오류가 없는 상태로 복구해야한다.
- Forward error recovery: 시스템이 계속 작동할 수 있는 새로운 상태를 찾는다.
- Backward error recovery: 시스템을 이전의 오류가 없는 상태로 되돌린다.
실무에서는 거의 후진 오류 복구를 사용하며, 이를 위해 복구 지점(recovery points)을 설정해야한다.
분산 시스템에서의 복구는 복잡하며, 프로세스들이 협력하여 복구를 시작할 일관된 상태를 식별해야한다.
Consistent Recovery State: 일관된 복구 상태
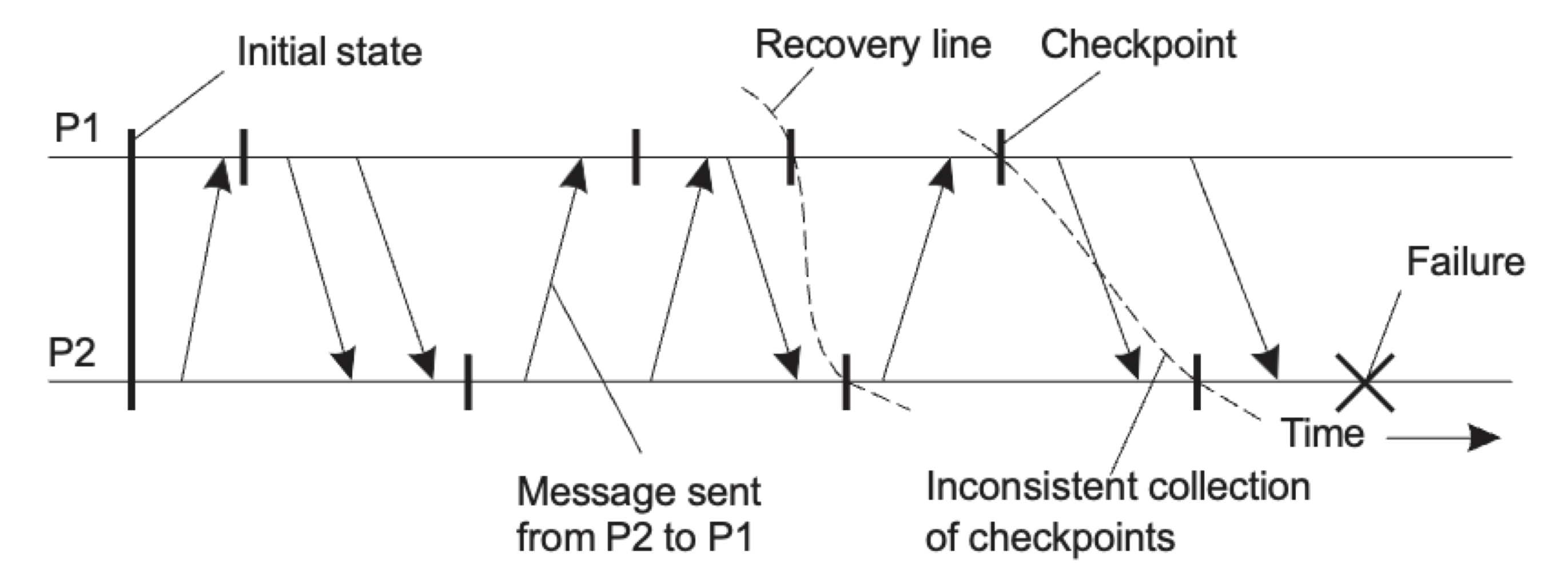
모든 수신된 메시지는 발신자의 상태에서도 전송된 것으로 나타나야한다. 즉, 메시지의 수신과 전송 간의 상태 불일치가 없어야한다.
Recovery line은 프로세스들이 정기적으로 자신의 상태를 checkpoint한다고 가정할 때, 가장 최근의 일관된 global checkpoint를 의미한다. 이는 모든 프로세스가 일관된 상태로 복구를 시작할 수 있는 지점을 나타낸다.
Independent Checkpointing: 독립적인 체크 포인트 설정
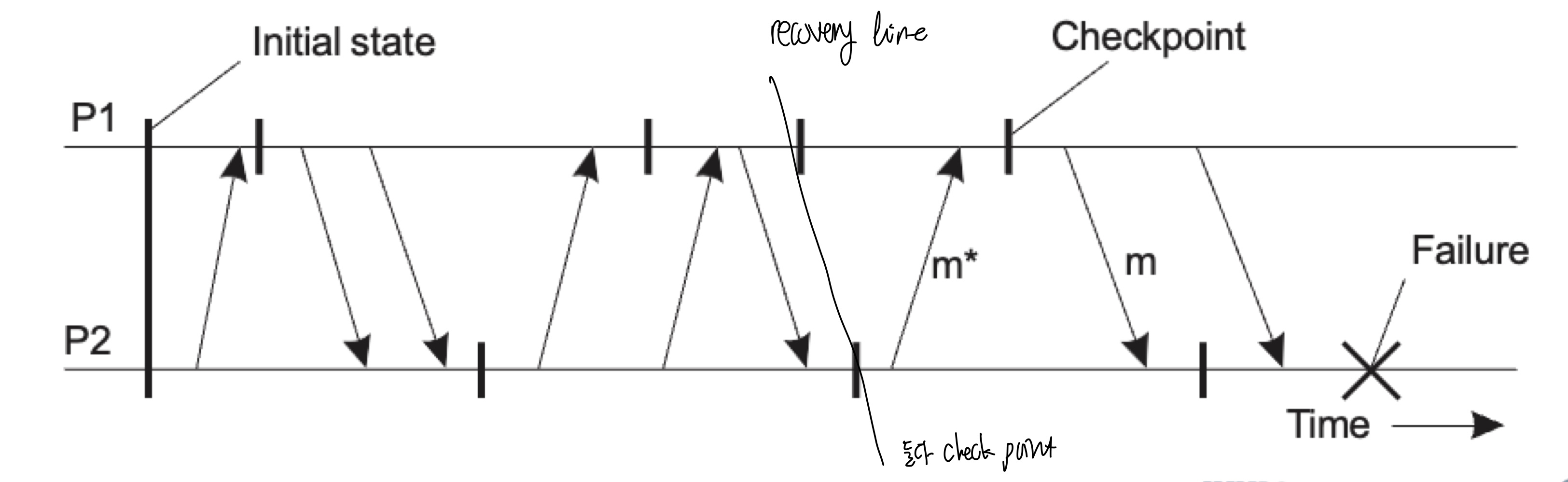
각 프로세스가 독립적으로 체크포인트를 설정하는 방법이다.
실패가 발생하면, consistent cut을 찾기 위해 이전 상태(recovery line)로 돌아간다.
체크포인트가 잘못된 시점에 수행되었다면, 복구선이 시스템 시작 지점으로까지 이동할 수 있다는 문제점이 있다.
이로 인해 연쇄적인 롤백 또는 도미노 효과가 발생할 수 있다. 프로세스 간의 상호 의존성으로 인해 하나의 실패가 전체 시스템의 이전 상태로의 롤백을 유발하는 것이다.
Message Logging
비용이 큰 체크포인트를 대신하여, 가장 최근 체크포인트에서 통신 동작을 재현하는 방법이다. 이를 위해 메시지를 로그에 저장한다.
단편적으로 결정적인 실행 모델(Piecewise Deterministic Exeution Model)을 가정한다.
각 프로세스의 실행은 상태 구간(state intervals)의 연속으로 가정할 수 있으며, 각 상태 구간은 비결정적 이벤트(e.g., 메시지 수신)로 시작한다. 상태 구간 내의 실행은 결정적이다.
비결정적인 이벤트를 기록한다면, 결정적인 실행 모델을 얻을 수 있으며, 이를 통해 완전한 재생이 가능해진다.
그렇다면 메시지는 언제 기록해야할까?
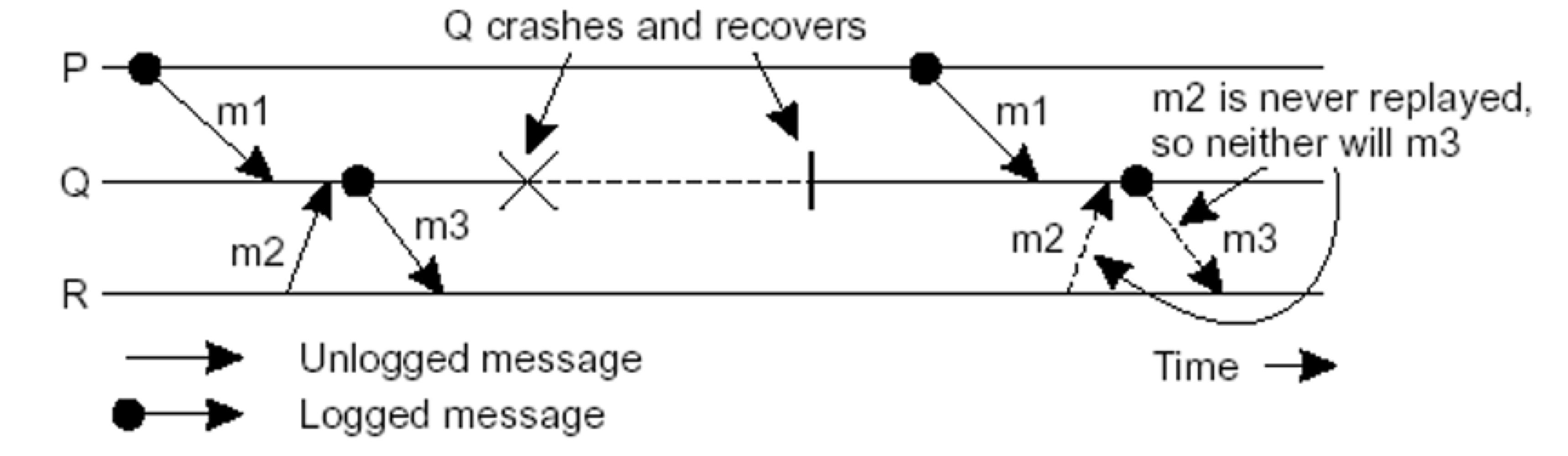
프로세스 Q가 메시지 m1과 m2를 수신한 후에 전달을 하는 상황이다. Q는 m1과 m2를 전달한 후 메시지 m3를 프로세스 R로 전송한다. 그러면 프로세스 R이 m3를 수신한 후에 전달을 하는 상황이다.
만약 m2가 로그되지 않은 경우라면?
Q가 실패하고 복구할 때, m2가 전달된 상태를 재현할 수 없다. 결과적으로, m3의 전송은 고아 메시지로 이어질 수 있다.
로깅은 고아 메시지가 발생하지 않도록 고안되어야 한다.
** 대학교 수업을 듣고 이해한 부분을 최대한 풀어서 작성한 글입니다.
틀린 정보가 존재할 수 있으며, 언제나 피드백은 환영입니다. **
'DKU > 분산처리' 카테고리의 다른 글
| Distributed System 18 (1) | 2024.12.15 |
|---|---|
| Distributed System 17 (0) | 2024.12.14 |
| Distributed System 15 (1) | 2024.11.21 |
| Distributed System 14 (1) | 2024.11.18 |
| Distributed System 13 (2) | 2024.11.11 |