
Hadoop Ecosystem
Big data
빅데이터는 방대한 양의 데이터를 의미하는 포괄적인 용어다.
이 데이터를 효율적으로 처리하기 위한 프레임워크와 연구 개발 (R&D) 이니셔티브를 포함한다.
빅데이터의 3V는 다음과 같다.
- Volume: 데이터의 방대한 크기
- Velocity(속도): 데이터의 생성 속도 및 처리 속도 요구사항
- Variety(다양성): 다양한 데이터 소스와 형식
빅데이터는 서로 다른 출처에서 발생하며, 크기와 형식도 다양하다.
Velocity는 데이터 생성 속도 뿐만 아니라 데이터 처리 속도를 포함한다.
Structured vs Unstructured Data
구조적 데이터는 고도로 조직화된 데이터로, 주로 관계형 데이터베이스(relational database)나 데이터 웨어하우스(data warehouse)에 저장된다. 검색이 용이하지만, 3V에 대한 유연성이 낮다.
비구조적 데이터는 혼합된 형식으로 제공되며, 보통 사전 처리(pre-processing)가 필요하다.
검색이 어렵고, 주로 NoSQL 데이터베이스나 데이터 레이크(data lakes)에 저장된다.
- 데이터 레이크: 혼합된 형식의 원시 데이터를 저장하기 위한 확장 가능한 스토리지 공간

Additional Dimensions: 추가적인 차원
빅데이터에는 고려해야 할 추가적인 3V가 존재한다.
- Veracity(정확성): 데이터의 품질 또는 신뢰성
- Value(가치): 데이터의 경제적 가치
- Variability(가변성): 위의 특정 중 하나 이상의 변동성을 의미
Challenges of Big Data: 빅데이터의 도전 과제
많은 양의 데이터를 다루는 사람이라면 다음과 같은 문제 중 하나 이상을 직면하게 될 가능성이 높다.
- 디스크 및 메모리 공간 부족
- 처리 속도 문제
- 하드웨어 결함
- 네트워크 용량 및 속도 제한
- 자원활용 최적화의 필요성
기존 기술로는 대량의 데이터를 효율적으로 처리하는데 한계가 존재하기 때문에, 분산 컴퓨팅을 사용한다.
분산 컴퓨팅은 적절한 시간과 자원을 사용하여 빅데이터를 처리할 수 있게 해준다.
Hadoop for Distributed Data Processing
하둡은 Apache Software Foundation의 오픈소스 프로젝트이며, 방대한 양의 데이터를 처리하는 계산을 용이하게 하기 위해 시작되었다.
하둡은 클러스터로 구성된 컴퓨터에서 작업을 실행하기 위한 프레임워크로, 하드웨어와 소프트웨어의 복잡성을 추상화하여 제공한다.
또한 데이터 저장, 데이터 분석, 조정을 위한 분산 시스템을 구축하는 도구를 제공한다.
Hadoop Features: 하둡의 특징
하둡은 빅데이터의 도전과제를 해결하기 위해 다음과 같은 기능을 제공한다.
- Scalability(확장성): 클러스터에 더 많은 노드를 추가하여 처리 능력을 확장 가능하다.
- Fault tolerance: 데이터 복제 및 작업 재시작 기능을 통해 하드웨어 오류에 강하다.
- High availability(고가용성): 데이터와 작업을 클러스터 내 여러 노드에 분산하여 시스템 가용성을 보장한다.
- Distributed cache/data locality: 데이터를 이동시키는 비용을 줄이기 위해 데이터가 저장된 노드에서 작업을 시작한다.
- Good abstraction of the underlying hardware(하드웨어 추상화): 사용자 친화적인 인터페이스 제공
- Cost-effectiveness(비용 효율성): 고급 하드웨어 없이도 작동 가능하다.
- 데이터는 SQL과 유사한 엔드포인트를 통해 쿼리가 가능하다.
Hadoop Core
하둡의 주요 구성 요소는 다음과 같다.
- Hadoop common: 하둡의 기본 라이브러리
- HDFS: Hadoop Distributed File System
- MapReduce
- YARN: Yet Another Resource Negotiator, 자원 관리 및 작업 스케줄링을 담당하는 리소스 관리자
HDFS: 하둡 분산 파일 시스템
HDFS는 데이터를 클러스터 전체에 분할하여 저장한다.
하드웨어 오류로 인한 데이터 손실이나 작업 중단을 방지하기 위해 HDFS는 다음과 같은 방법을 사용한다.
- Replication: 데이터를 여러 복제본으로 생성한다. 일반적으로 3개의 복사본을 생성한다.
- Erasure coding(소멸 코딩): 데이터를 조각화하여 일부 손실이 발생해도 복구할 수 있도록 저장한다.
복제 또는 소멸 코딩으로 얻어진 데이터의 중복은 하둡의 결함허용의 기반이 된다.
소멸 코딩은 데이터를 보호하기 위한 방법으로 데이터를 조각으로 나누고, 이를 확장 및 인코딩하여 중복 데이터 조각과 함께 다양한 위치 또는 저장매체에 분산하여 저장하는 기술이다.
HDFS Architecture
일반적인 하둡 클러스터의 구성요소는 다음과 같다.
- NameNode: 하둡 클러스터의 주요 접근 지점이다. DataNode에 분산 저장된 데이터를 관리하며, 파일 시스템 메타데이터를 관리하고, 작업 부하를 조정(로드밸런싱)한다.
- Secondary NameNode: NameNode의 변경 사항을 정기적으로 스냅샷으로 저장하여 추적한다. 빠른 시작을 지원하며, NameNode가 단일 장애 지점이므로 고가용성 보장을 위해 필요하다.
- Multiple DataNodes: 데이터가 실제로 저장되고 계산이 수행되는 노드다. 데이터를 저장하며 작업을 실행하며, "data and worker noes"라고 불리는 것이 더 적합하다.
- 내부 데이터 표현: 하둡은 데이터를 여러 블록으로 간주하며, 기본 블록의 크기는 128MB이다. 여러 파일을 단일 파일과 동일한 방식으로 처리하며, 입력이 단일 파일이 아닌 디렉터리인 경우에는 디렉터리 내의 모든 파일을 처리한다.
- DataNode 장애: 각 데이터노드는 주기적으로 Heartbeat 메시지를 NameNode에 전송하여 가용성을 알린다. 데이터노드가 네트워크나 하드웨어 문제로 인해 사용할 수 없게 되면, Namenode는 해당 노드에 요청을 중단하며 해당 노드에 저장된 블록의 새 복제본을 다른 노드에 생성한다.
- Write Once Read Many(WORM): 파일은 한 번 생성, 쓰기, 닫기 후 변경되지 않아야한다. 단 추가(Append) 및 잘라내기(Truncate)는 가능하다. 파일의 내용을 끝에 추가하는 것은 지원되지만, 임의의 지점에서 업데이트는 불가능하다. 이러한 설계는 데이터 일관성 문제를 단순화하고, 높은 처리량의 데이터 접근을 가능하게 한다.
MapReduce
구글 검색 엔진에서 대량의 데이터를 분할, 처리, 집계하는데 사용된 방법이다.
MapReduce의 오픈소스 버전은 이후 Apache Hadoop 프로젝트 내에서 공개되었다.
MapReduce는 함수형 프로그래밍에서 일반적으로 사용되는 계산 모델에서 영감을 받았다.
데이터셋의 각 항목에 동일한 함수를 독립적으로 적용하여 변환(Map)하거나 정리(Reduce)하는 방식이 분산 환경에서 효과적으로 작동한다.
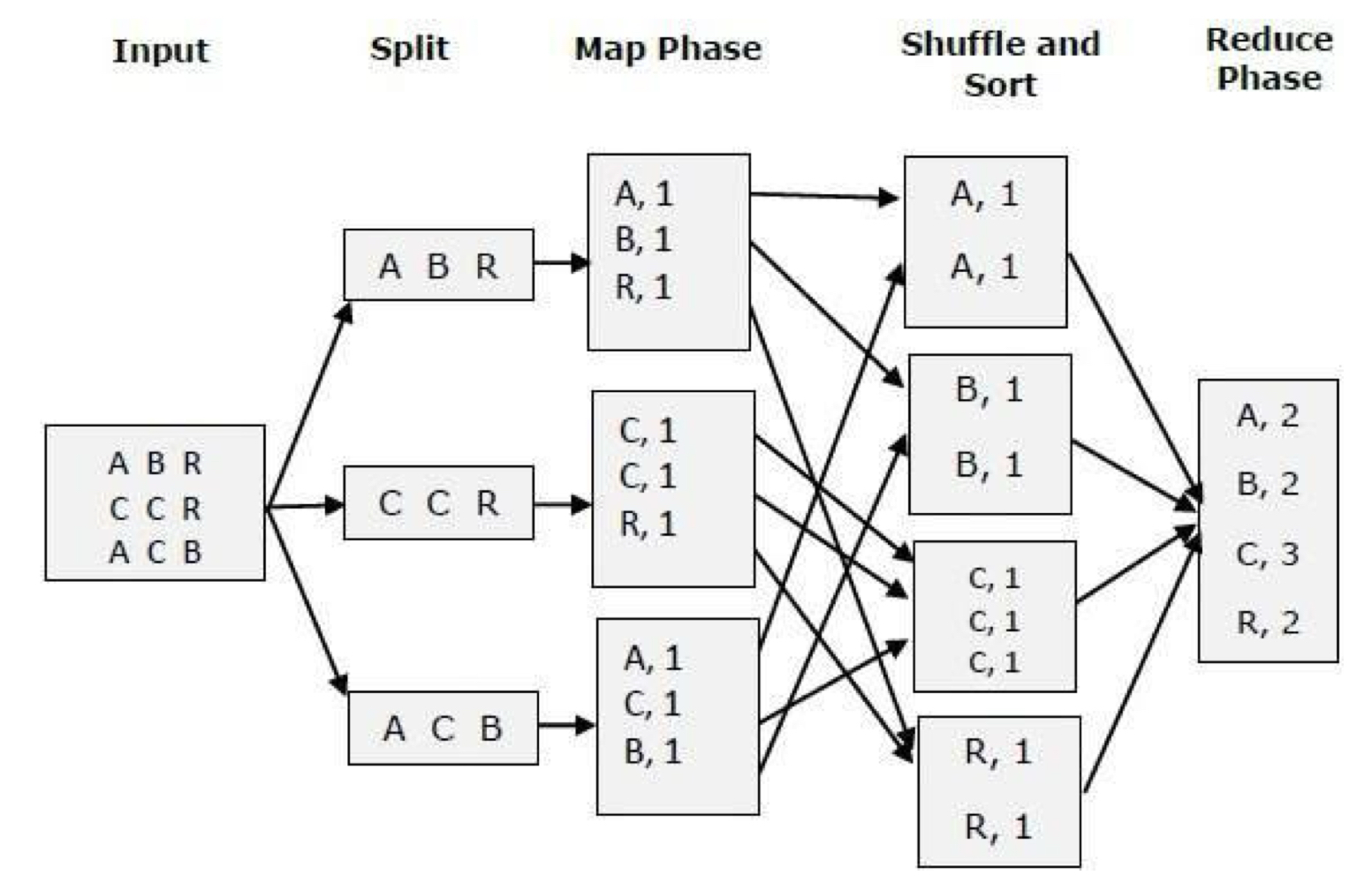
MapReduce의 작업 단계는 다음과 같다.
- Split: 데이터를 여러 컴퓨터 노드에 걸쳐 분할한다.
- Map: 분할된 데이터 조각에 대해 맵 함수를 적용한다.
- Sort and Shuffle: 맵 함수의 출력 결과를 저장하고, reducer로 분배한다.
- Reduce: 최종적으로 데이터에 reduce function을 적용하여 결과를 생성한다.
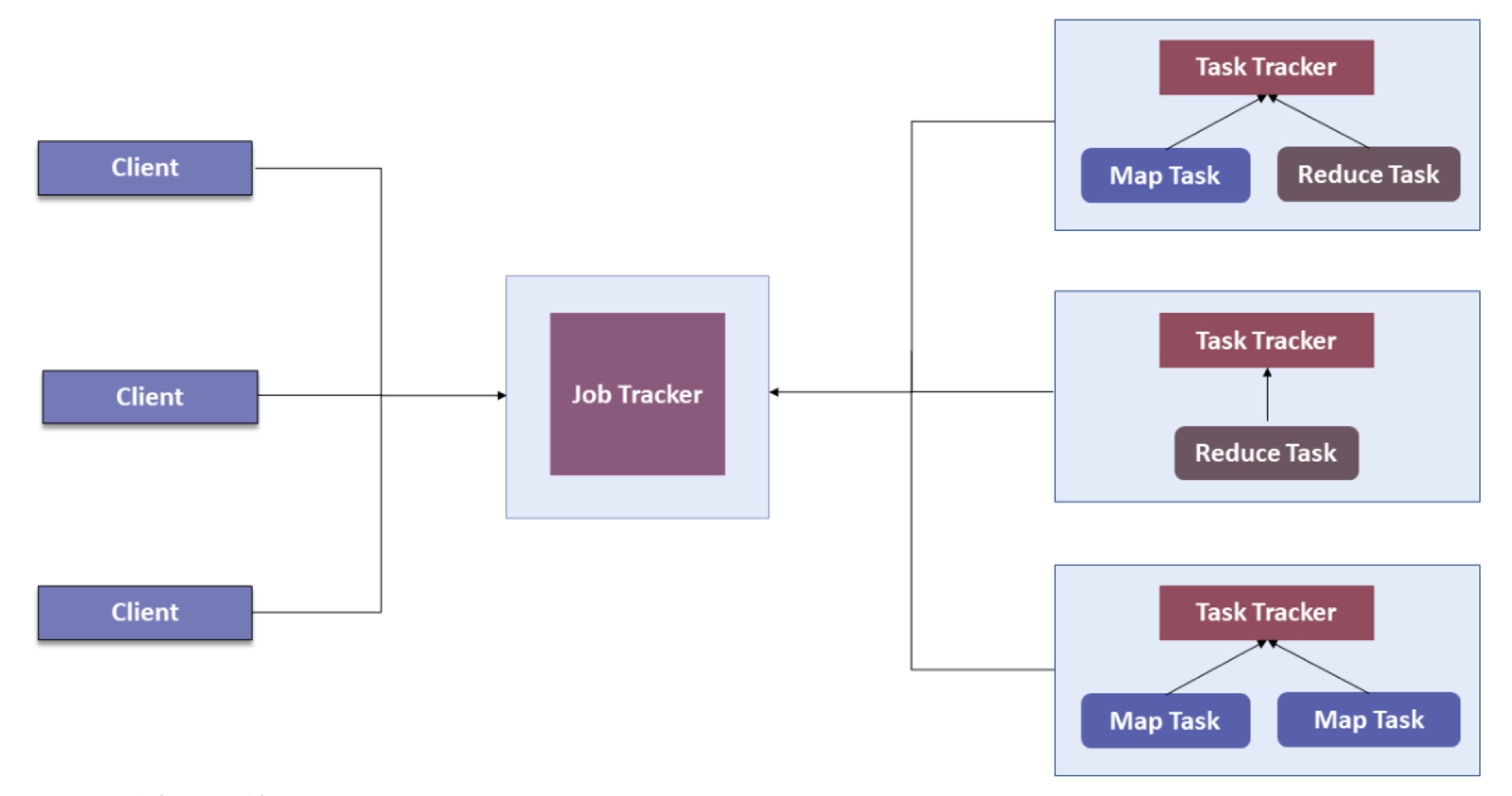
YARN
단일 마스터 노드(Job Tracker)는 자원 할당, 작업 스케줄링, 실행 중인 모든 작업 모니터링을 모두 수행한다.
결과적으로 병목현상이 발생하며, 자원을 비효율적으로 할당하게 된다.
이러한 문제 해결을 위해 YARN이 도입되었다. YARN은 하둡 작업을 관리하고, 자원 할당과 작업 스케줄링을 책임진다.
YARN의 메인 아이디어는, 자원 관리와 작업 스케줄링/모니터링을 분리하는 것이다.
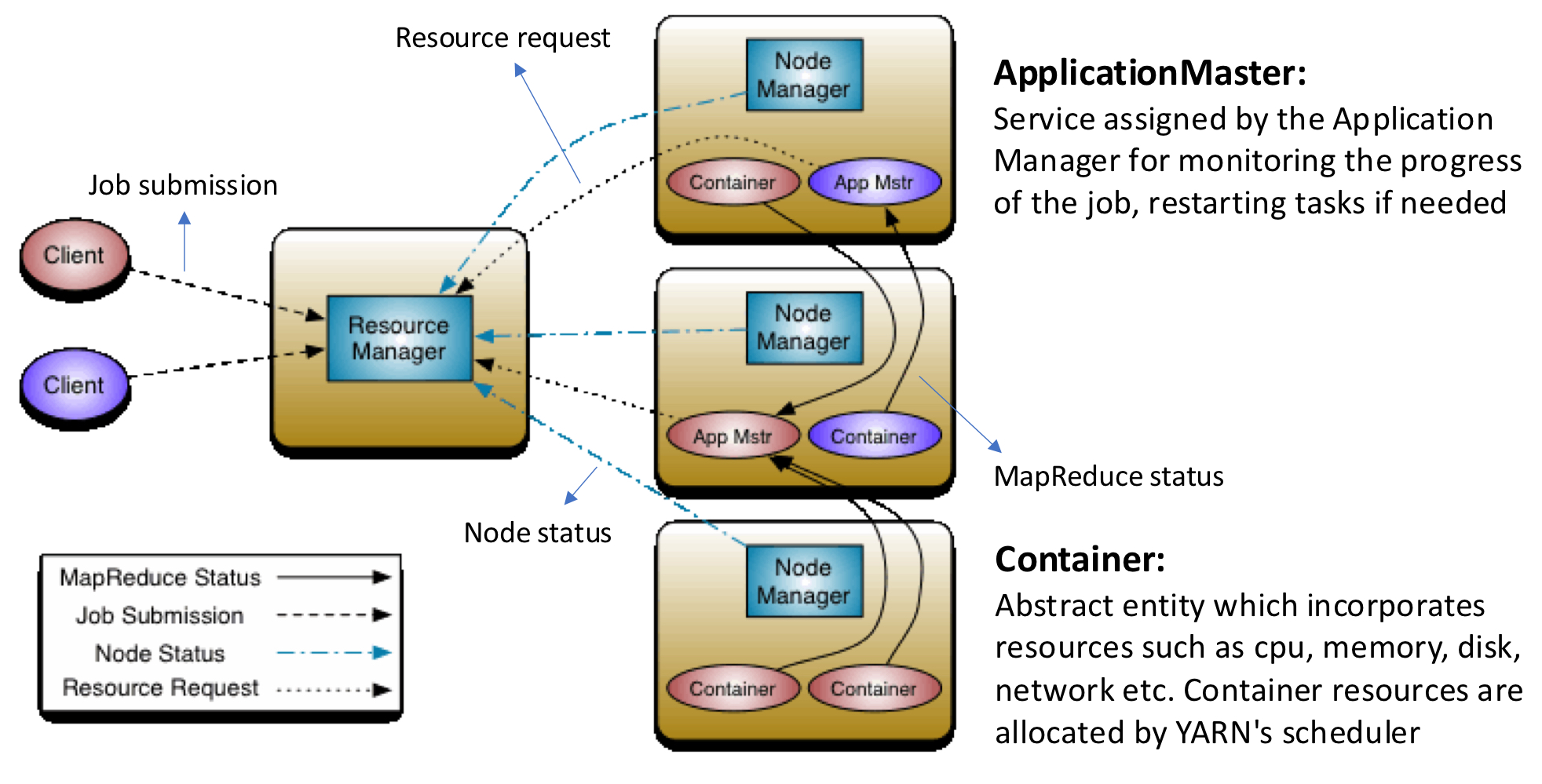
- ApplicationMaster: ApplicaitonManager에 의해 할당된 서비스다. 작업 진행 상황을 모니터링하며, 필요 시 작업을 재시작한다.
- Container: CPU, 메모리, 디스크, 네트워크 등과 같은 자원을 포함하는 추상 엔터티이다. YARN의 스케줄러에 의해 자원이 할당된다.
- ResourceManager: 클러스터에 있는 자원을 관리하는 서비스이다.
- NodeManager: 각 노드에 할당된 작업을 실행하기 위한 서비스이다.
** 대학교 수업을 듣고 이해한 부분을 최대한 풀어서 작성한 글입니다.
틀린 정보가 존재할 수 있으며, 언제나 피드백은 환영입니다. **
'DKU > 분산처리' 카테고리의 다른 글
| Distributed System 19 (3) | 2024.12.15 |
|---|---|
| Distributed System 17 (0) | 2024.12.14 |
| Distributed System 16 (1) | 2024.12.13 |
| Distributed System 15 (1) | 2024.11.21 |
| Distributed System 14 (1) | 2024.11.18 |