
Apache Projects
이전 글에서 작성된 MapReduce는 단일 처리에는 효율적이지만, 다단계 알고리즘에서는 비효율적이다.
데이터 공유를 위한 효율적인 기본 기능이 없으며, 단계 간 상태는 분산 파일 시스템으로 저장되어 복제 및 디스크로의 저장으로 인해 속도가 느려지기 때문이다.
Disk-based framework(e.g., MapReduce)는 중간 결과를 디스크에 저장하며, 각 쿼리마다 데이터를 디스크에서 다시 로드한다. 따라서 장애 복구가 용이하다. ETL(Extract, Transform, Load)와 같은 작업에 적합하다.
Memory-based framework(e.g., Spark)는 중간 결과를 메모리에 유지하여 I/O 비용을 절감한다. 따라서 메모리 가용성에 민감하다. 데이터셋에 적용된 연산을 기억하여 반복 계산을 최소화한다. 반복적 워크로드에 적합하다.
Spark Compute Engine
스파크는 구조적 API와 비구조적 API를 제공하며, HDFS, Cassandra, Kafka 시스템과 통합되어있다.
데이터 프로세싱, 통계, 데이터 프로세싱의 스트리밍, 머신 러닝 등에 사용된다.

Resilient Distributed Datasets(RDDs)
스파크에서 가장 핵심적인 객체다.
연산 중 해당 단계의 데이터를 표현하며, 대규모 변환(Coarse-grained transformation)을 지원한다.
계통(lineage)을 사용하여 장애를 효율적으로 복구한다.
- 하나의 작업을 여러 요소에 적용한 내역을 기록한다.
- 장애 발생 시 데이터셋의 손실된 파티션을 재계산한다.
- 실패가 없다면 복구에 비용이 들지 않는다.
RDD Transformations에는 Lazy Operation(지연 실행)가 있다.
RDD에 적용된 지연 연산으로, 새로운 RDD를 생성한다. 스파크가 최적화를 수행할 수 있도록 지원한다.
(e.g., map, filter, union, intersection, distinct, reduceByKey, groupByKey)
RDD는 연산 후 값을 드라이버 프로그램에 반환한다.
(e.g., reduce, collect, count, first, take, saveAsFile)
Apache Pig
Apache Pig는 MapReduce를 추상화한 도구로, 대규모 데이터 세트를 분석하기 위해 데이터의 흐름을 표현한다.
Pig Latin은 데이터 분석 프로그램을 작성하기 위한 고수준 언어이며, 인터프리터 언어다. Pig Latin으로 작성된 스크립트는 MapReduce 작업으로 변환되어 실행된다.
Joins 및 aggergations(집계) 작업에 주로 사용된다.
MapReduce만 사용하여 어떤 작업을 수행한다면, 자바를 쓰는 것보다 Pig Latin을 쓰는 것이 코드가 훨씬 간결하게 나온다.
Apache Hive
구조화된 데이터를 관리하고 쿼리하기 위한 도구로, 하둡 위에서 작동한다.
MapReduce를 사용하여 실행하고, 저장을 위해 HDFS를 사용한다. 다른 데이터 저장소와 통합이 가능하다.
하이브는 구조화된 데이터에서 SQL을 활용하고, 데이터웨어하우징 툴과 유사한 환경을 제공한다.
플러그 가능한 MapReduce 스크립트를 사용할 수 있고, 풍부하고 사용자 정의 가능한 데이터 타입을 지원하며, 사용자 정의 함수를 지원하기 때문에 확장성이 좋다.
다양한 파일 및 데이터 형식을 지원하기 위한 확장 가능한 프레임워크를 제공하기 때문에 상호운용성이 좋다.
- SQL 지원
- JDBC/ODBC 지원
- 유연한 데이터 타입: 구조체, 맵, 배열, JSON객체 지원
- 사용자 정의 함수 및 집계
- 정규 표현식 지원
- MapReduce 지원
- 파티션과 버킷
Apache HBase
HBase는 HDFS 위에 구축된 NoSQL 데이터 저장소이다.
HBase는 Column family-oriented database(컬럼-패밀리 지향 데이터베이스)이다.
데이터를 빠르게 검색하거나 MapReduce를 통해 배치 처리가 가능하다.
대규모 데이터를 처리하거나, 고성능 처리가 필요하거나, 컬럼 수가 가변적일 때나, 랜덤 읽기와 쓰기가 필요할 때 사용한다.
HBase에는 HMaster가 존재하는데, 리전 서버를 조정하고 테이블 변경을 관리한다.
메타 테이블(HBase 카탈로그 테이블)은 리전의 위치를 관리한다.
클라이언트는 메타 테이블에 행 키(row key)를 요청하여 해당 리전 서버를 확인한다.
이후, 확인된 리전 서버에서 연결된 행을 읽는다.
Apache ZooKeeper
분산 애플리케이션을 위한 고성능 조정 서비스이다. 분산된 프로세스가 데이터 레지스터의 공유 계층적 네임스페이스를 통해 상호 조정이 가능하다.
주키퍼는 단순한 분산 락 시스템이 아니라, 다양한 분산 시스템 기능을 지원한다.
DNS같은 네이밍 서비스를 지원하고, 중앙화된 소스로부터 초기 설정을 부트스트랩하는 구성 관리가 있다. 노드의 가입/탈퇴 및 노드 상태를 실시간으로 관리할 수 있는 분산 클러스터 관리 기능이 있다. 락, 배리어, 큐와 같은 분산 동기화 메커니즘을 제공하며, 리더 선출과 같은 그룹 관리 작업을 지원한다.
Apache Cassandra
분산된 NoSQL 데이터베이스다.
- 수평적 확장성(Horizontal Scalability): 노드 간 데이터 리밸런싱
- 고가용성: 마스터리스 아키텍처로 구성되며, 단일 장애 지점이 없다.
- 구조화된 레코드: 테이블, 행, 열의 구조과 관계형 데이터베이스와 유사하다.
- 쓰기 최적화: 데이터를 수정하지 않고 새로운 데이터를 추가하는 방식으로 설계되었고, RDB는 읽기 성능 최적화에 중심을 두는 반면, Cassandra는 쓰기 선응에 중점을 둔다.
- 보조 인덱스: RDB에 비해 성능이 뛰어나지는 않지만, 상대적으로 양호한 성능을 보일 수 있다.
카산드라는 마스터리스 아키텍처이며, 대규모 데이터 트랜잭션(실시간 트랜잭션)에 높은 성능을 제공한다. 수평적 확장과 높은 가용성을 제공한다. 하지만 데이터의 원자적 업데이트가 어려우며(eventual consistency), 복잡한 조건으로 검색하는 것이 어렵다. 그리고 최소 3개의 노드가 필요하다.
HBase는 마스터-슬레이브 아키텍처이며, 읽기 성능이 상대적으로 빠르다. 높은 데이터 일관성을 요구하는 대규모 데이터 처리에 적합하며, 수십 테라바이트 이상의 빅데이터 처리에 적합하다. 최소 5개의 노드가 필요하다.
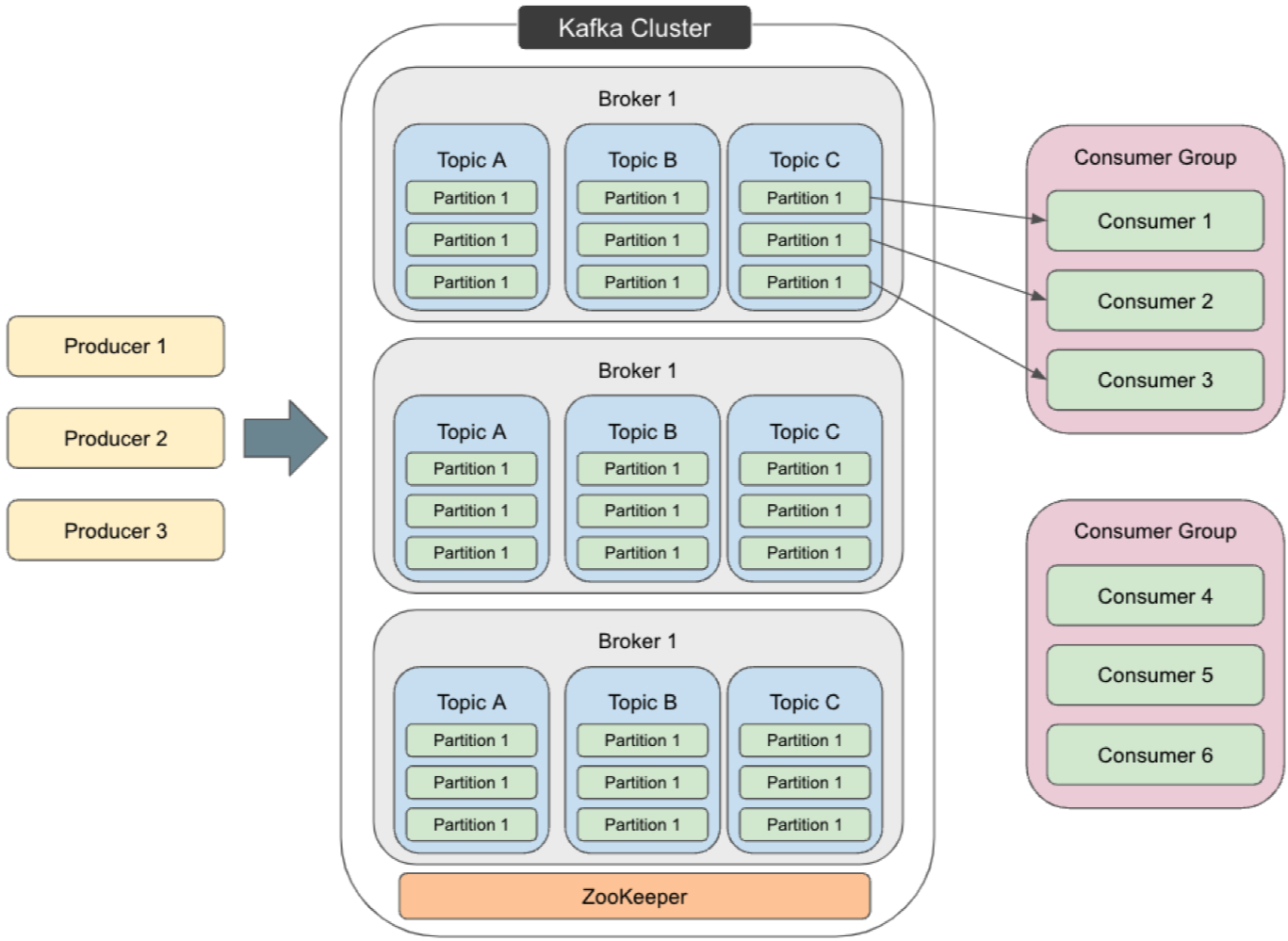
Apache Kafka
고성능 publish/subscribe 메시징 시스템이며, 분산 커밋 로그 개념에 기반한다.
Kafka의 메시지는 분산되었고, 내구성있고 순서대로 저장되며, 결정적으로 읽기가 가능하다.
프로듀서는 토픽을 브로커에게 보내고, 크로커는 토픽을 컨슈머에게 보낸다.
토픽은 여러 브로커에 분산되어 저장되고, 동일한 키를 가진 메시지는 항상 동일한 파티션에 저장된다.
** 대학교 수업을 듣고 이해한 부분을 최대한 풀어서 작성한 글입니다.
틀린 정보가 존재할 수 있으며, 언제나 피드백은 환영입니다. **
'DKU > 분산처리' 카테고리의 다른 글
| Distributed System 18 (1) | 2024.12.15 |
|---|---|
| Distributed System 17 (0) | 2024.12.14 |
| Distributed System 16 (1) | 2024.12.13 |
| Distributed System 15 (1) | 2024.11.21 |
| Distributed System 14 (1) | 2024.11.18 |